Summarize Google News Results with LangChain and Serper API
A brief guide to Google news search and AI-generated summaries with LangChain LLM framework and Serper API.
In previous posts, I have experimented with LangChain to generate text and document summaries, prototype flows, and more. This time, I'll use LangChain and Serper API to summarize news search results.
What is Google Serper API?
LangChain is an open-source framework created to aid the development of applications leveraging the power of large language models (LLMs). It can be used for chatbots, text summarisation, data generation, code understanding, question answering, evaluation, and more. Serper, on the other hand, allows you to submit queries and receive Google Search (SERP) results quickly and cost effectively.
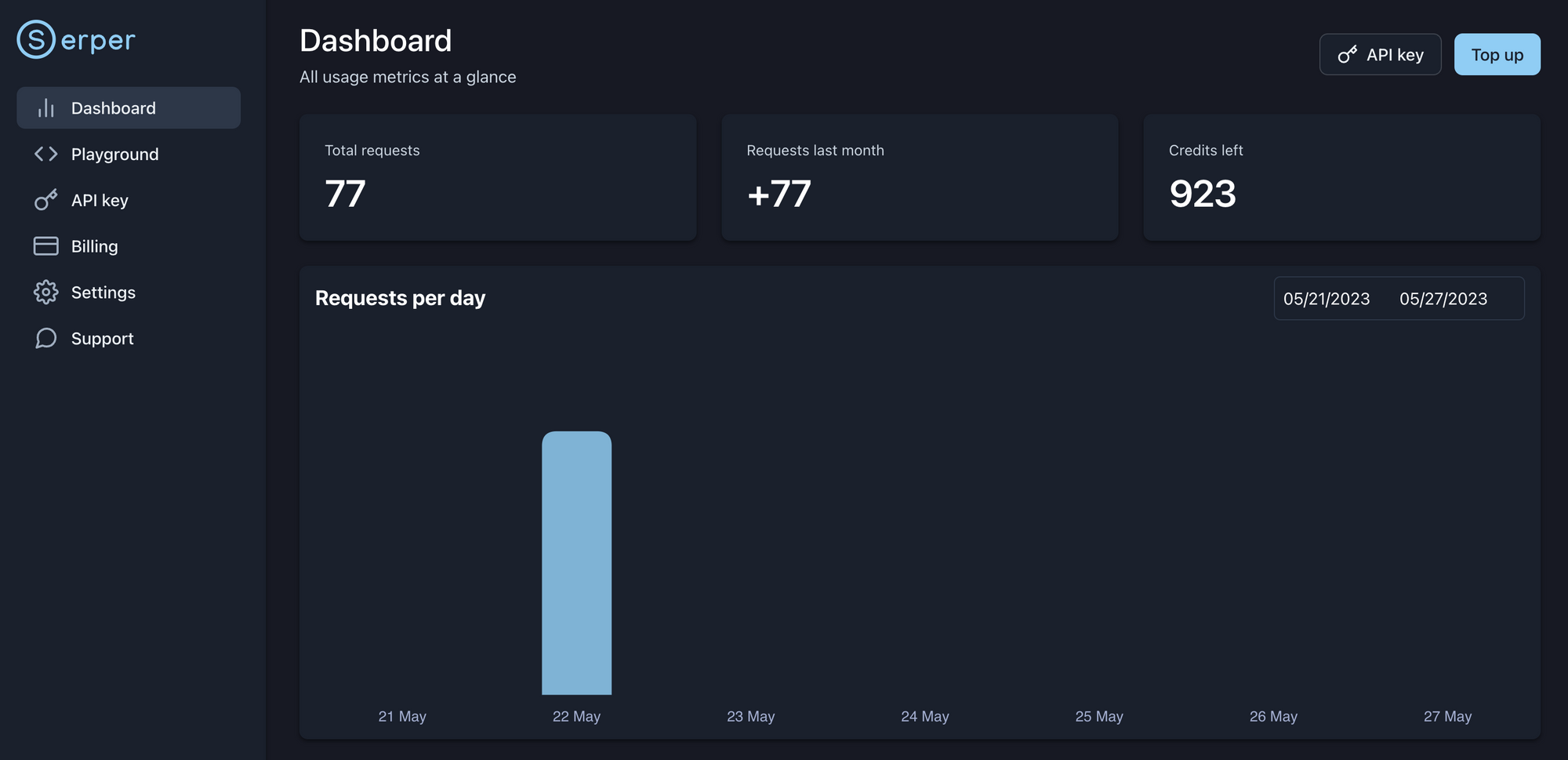
Sign up for an account with Serper, or log in if you already have an account, and create an API key. Serper offers a generous free tier; as you consume the API, the dashboard will populate with the requests and remaining credits.
Build a Streamlit App with LangChain and Serper
Streamlit is an open-source Python library that allows you to create and share interactive web apps and data visualisations in Python with ease. I'll use Streamlit to create a simple app that retrieves the latest search results for a particular topic. Wait, isn't that just like Google? Yep, but we'll also retrieve the content for each result in real-time, and summarize it for you. Sort of a Blinkist for search results!
The app uses the GoogleSerperAPIWrapper module to retrieve relevant news search results using Serper API, loads content for each using the UnstructuredURLLoader module, and finally leverages the gpt-3.5-turbo chat model using the ChatOpenAI module to summarize each result. Here's an excerpt from the streamlit_app.py file - you can find the complete source code on GitHub. Note that this is just proof-of-concept code; it has not been developed or optimized for production usage.
import streamlit as st
from langchain.prompts import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import UnstructuredURLLoader
from langchain_community.utilities import GoogleSerperAPIWrapper
# Streamlit app
st.subheader('Last Week In...')
# Get OpenAI API key, Serper API key, number of results, and search query
with st.sidebar:
openai_api_key = st.text_input("OpenAI API Key", value="", type="password")
serper_api_key = st.text_input("Serper API Key", value="", type="password")
num_results = st.number_input("Number of Search Results", min_value=3, max_value=10)
st.caption("*Search: Uses Serper API only, retrieves search results.*")
st.caption("*Search & Summarize: Uses Serper & OpenAI APIs, summarizes each search result.*")
search_query = st.text_input("Search Query", label_visibility="collapsed")
col1, col2 = st.columns([1,3])
# If the 'Search' button is clicked
if col1.button("Search"):
# Validate inputs
if not openai_api_key.strip() or not serper_api_key.strip() or not search_query.strip():
st.error(f"Please provide the missing fields.")
else:
try:
with st.spinner("Please wait..."):
# Show the top X relevant news articles from the previous week using Google Serper API
search = GoogleSerperAPIWrapper(type="news", tbs="qdr:w1", serper_api_key=serper_api_key)
result_dict = search.results(search_query)
if not result_dict['news']:
st.error(f"No search results for: {search_query}.")
else:
for i, item in zip(range(num_results), result_dict['news']):
st.success(f"Title: {item['title']}\n\nLink: {item['link']}\n\nSnippet: {item['snippet']}")
except Exception as e:
st.exception(f"Exception: {e}")
# If 'Search & Summarize' button is clicked
if col2.button("Search & Summarize"):
# Validate inputs
if not openai_api_key.strip() or not serper_api_key.strip() or not search_query.strip():
st.error(f"Please provide the missing fields.")
else:
try:
with st.spinner("Please wait..."):
# Show the top X relevant news articles from the previous week using Google Serper API
search = GoogleSerperAPIWrapper(type="news", tbs="qdr:w1", serper_api_key=serper_api_key)
result_dict = search.results(search_query)
if not result_dict['news']:
st.error(f"No search results for: {search_query}.")
else:
# Load URL data from the top X news search results
for i, item in zip(range(num_results), result_dict['news']):
loader = UnstructuredURLLoader(urls=[item['link']], ssl_verify=False, headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13_5_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"})
data = loader.load()
# Initialize the ChatOpenAI module, load and run the summarize chain
llm = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)
prompt_template = """Write a summary of the following in 100-150 words:
{text}
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="stuff", prompt=prompt)
summary = chain.run(data)
st.success(f"Title: {item['title']}\n\nLink: {item['link']}\n\nSummary: {summary}")
except Exception as e:
st.exception(f"Exception: {e}")
Deploy the Streamlit App on Railway
Railway is a modern app hosting platform that makes it easy to deploy production-ready apps quickly. Sign up for an account using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the LangChain Apps one-click starter template (or click the button below) to deploy the app instantly on Railway.

This template deploys several services - search, text summary, document summary, news summary (this one), and more. For each, you'll be given an opportunity to change the default repository name and set it private, if you'd like. Since you are deploying from a monorepo, configuring the first app should suffice. Accept the defaults and click Deploy; the deployment will kick off immediately.
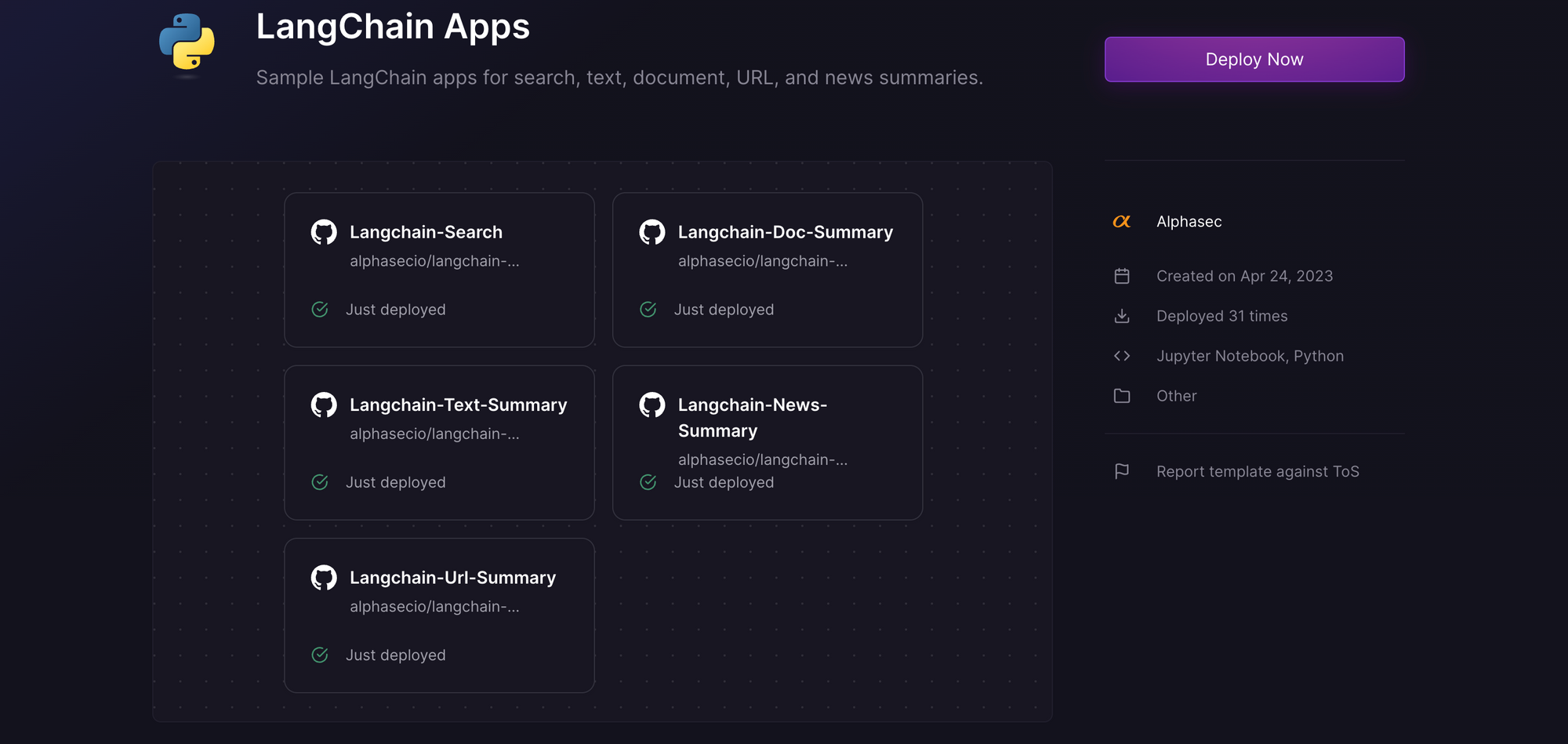
Once the deployment completes, the Streamlit apps will be available at default xxx.up.railway.app domains - launch each URL to access the respective app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.

Provide the OpenAI and Serper API keys, the number of search results to be retrieved, the search query, and click on Search or Search & Summarize. If you don't have an OpenAI API key, you can get it here.
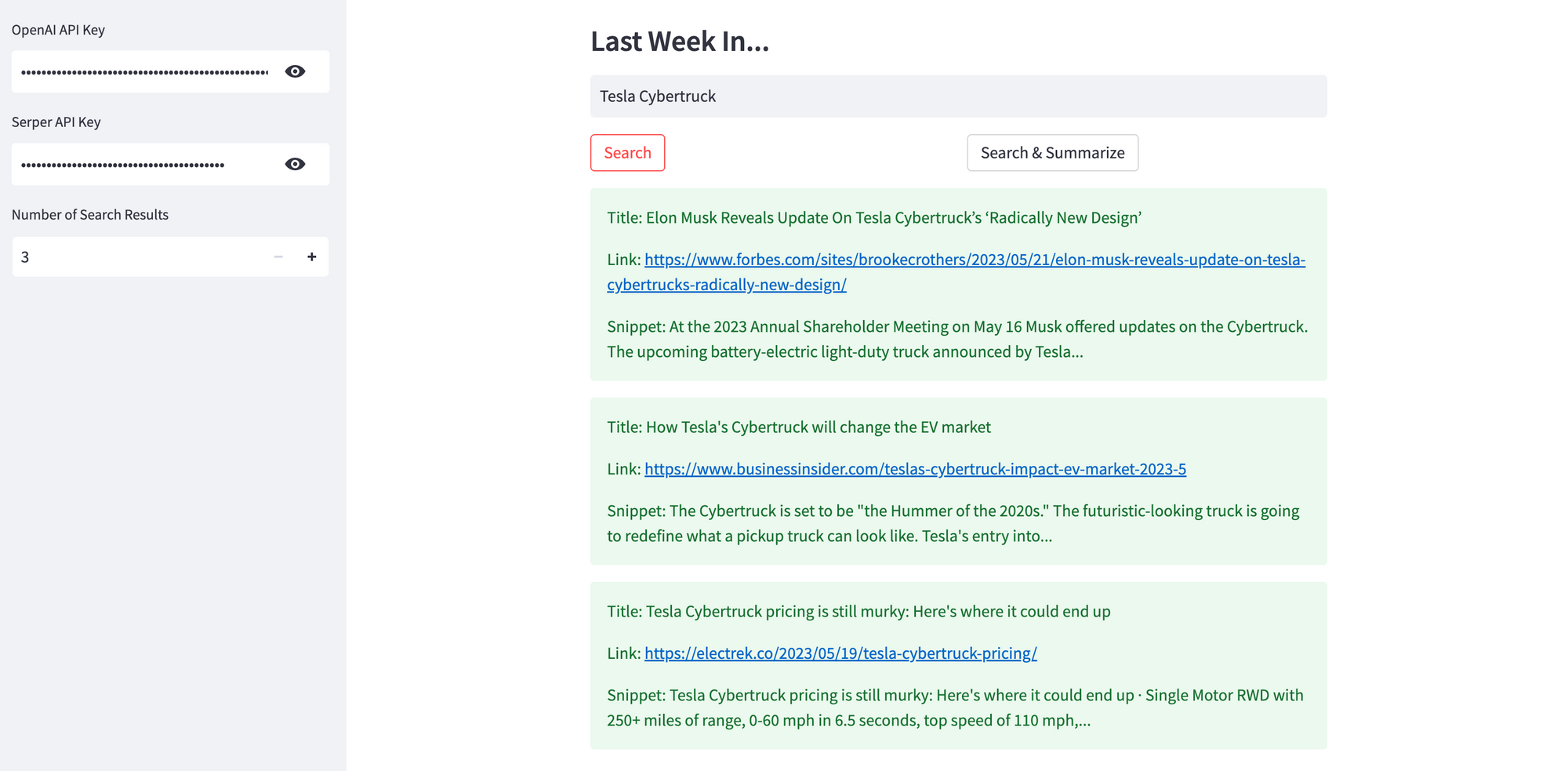
If you clicked Search, you'll get the top X (Number of Search Results, between 3 and 10) news search results, with the title, link, and a short snippet for each result. This option does not use the OpenAI API.
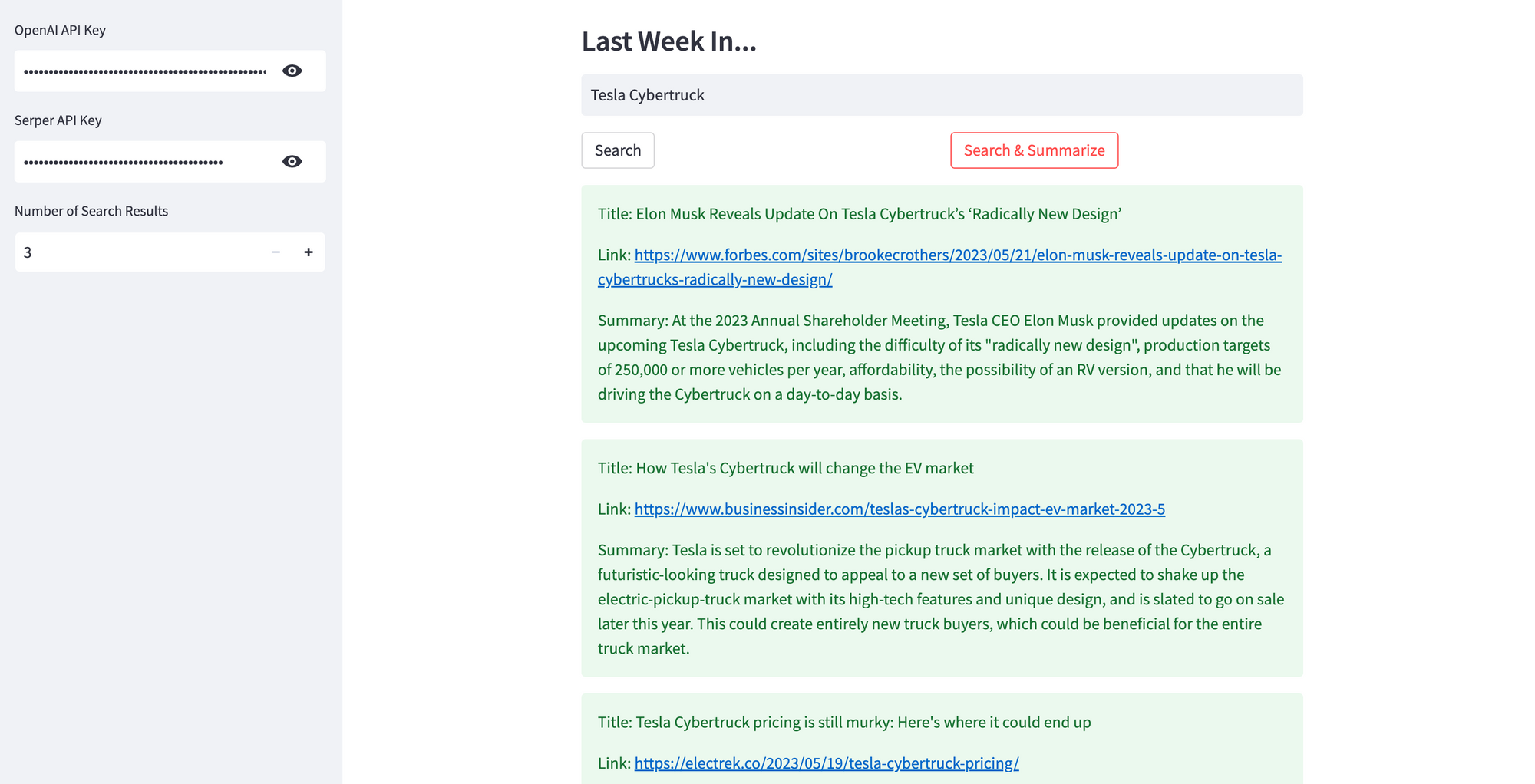
If you clicked Search & Summarize, you'll get the top X (Number of Search Results, between 3 and 10) news search results, with the title, link, and an OpenAI-generated summary for each result. I've restricted the number of search results to 10, and I'm using a chat model instead of the default language model, to ensure that each search does not blow up your OpenAI costs.