Summarize Documents with LangChain and Chroma
A brief guide to summarizing documents with LangChain and Chroma vector store.
In my previous post, we explored an easy way to build and deploy a web app that summarized text input from users. However, that approach does not work well for large or multiple documents, where there is a need to generate and store text embeddings in vector stores or databases. This is where Chroma, Weaviate, Pinecone, Milvus, and others come in handy. If you want to understand the role of embeddings in more detail, see my post on LangChain Embeddings first. In this post, we'll create a simple Streamlit application that summarizes documents using LangChain and Chroma.
Build a Streamlit App with LangChain for Summarization
LangChain is an open-source framework created to aid the development of applications leveraging the power of large language models (LLMs). It can be used for chatbots, text summarisation, data generation, code understanding, question answering, evaluation, and more. Chroma, on the other hand, is an open-source, lightweight embedding (or vector) database that can be used to store embeddings locally. Together, developers can easily and quickly create AI-native applications.
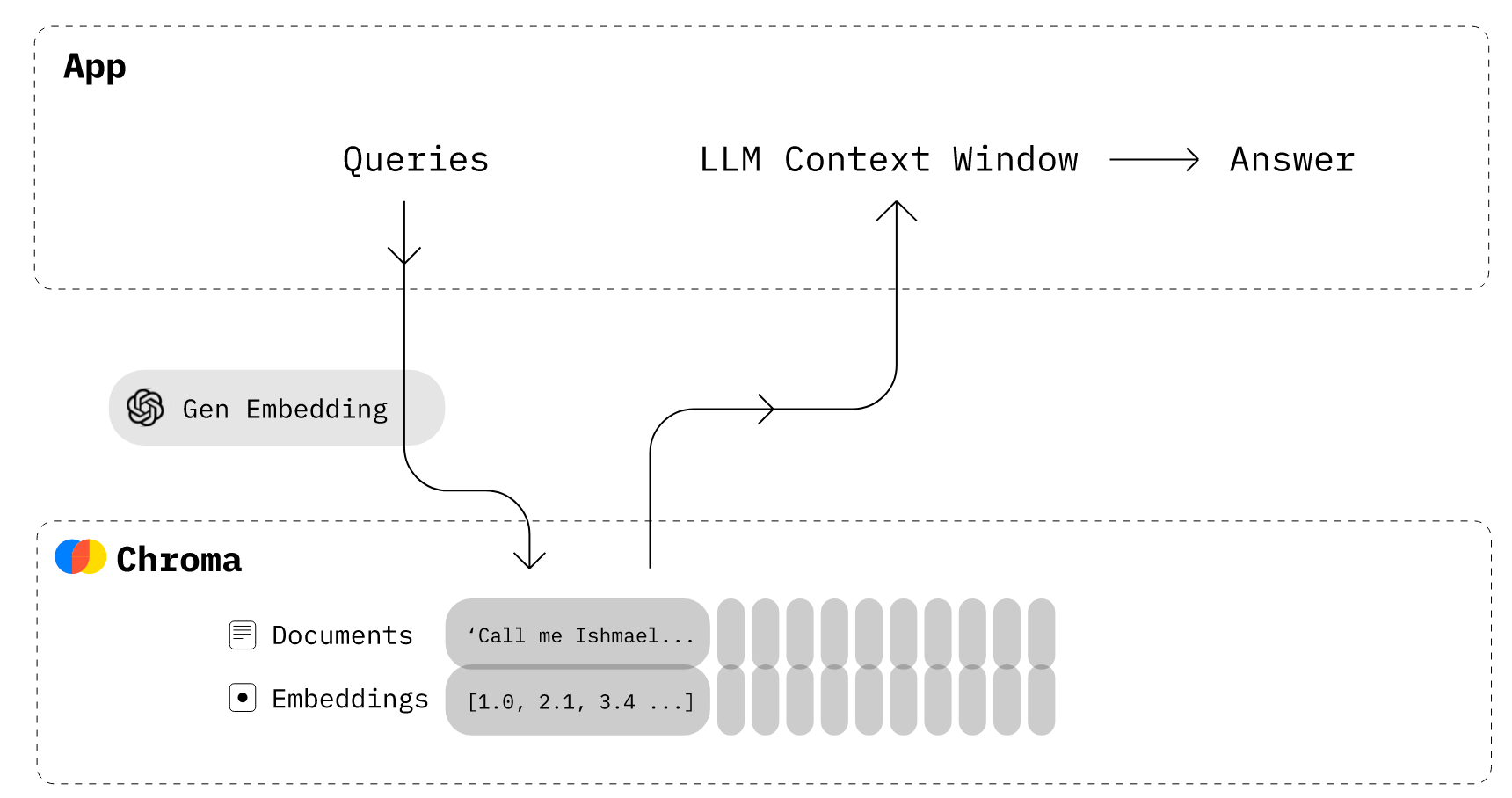
Chroma provides wrappers around the OpenAI embedding API, which uses the text-embedding-ada-002 second-generation model. By default, Chroma uses an in-memory DuckDB database; it can be persisted to disk in the persist_directory folder on exit and loaded on start (if it exists), but will be subject to the machine's available memory. Chroma can also be configured to run in a client-server mode, where the database runs from the disk instead of memory. See the docs for the steps to persist the Chroma database.
To summarize the document, we first split the uploaded file into individual pages, create embeddings for each page using the OpenAI embeddings API, and insert them into the Chroma vector database. Then, we retrieve the information from the vector database using a similarity search, and run the LangChain Chains module to perform the summarization over the input.
Here's an excerpt from the streamlit_app.py file (without persistence) - you can find the complete source code on GitHub. Shoutout to the official LangChain docs - much of the code is borrowed or influenced by it.
import os, tempfile
import streamlit as st
from langchain.llms.openai import OpenAI
from langchain.vectorstores.chroma import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import PyPDFLoader
# Streamlit app
st.subheader('LangChain Doc Summary')
# Get OpenAI API key and source document input
openai_api_key = st.text_input("OpenAI API Key", type="password")
source_doc = st.file_uploader("Upload Source Document", type="pdf")
# If the 'Summarize' button is clicked
if st.button("Summarize"):
# Validate inputs
if not openai_api_key.strip() or not source_doc:
st.error(f"Please provide the missing fields.")
else:
try:
with st.spinner('Please wait...'):
# Save uploaded file temporarily to disk, load and split the file into pages, delete temp file
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(source_doc.read())
loader = PyPDFLoader(tmp_file.name)
pages = loader.load_and_split()
os.remove(tmp_file.name)
# Create embeddings for the pages and insert into Chroma database
embeddings=OpenAIEmbeddings(openai_api_key=openai_api_key)
vectordb = Chroma.from_documents(pages, embeddings)
# Initialize the OpenAI module, load and run the summarize chain
llm=OpenAI(temperature=0, openai_api_key=openai_api_key)
chain = load_summarize_chain(llm, chain_type="stuff")
search = vectordb.similarity_search(" ")
summary = chain.run(input_documents=search, question="Write a summary within 200 words.")
st.success(summary)
except Exception as e:
st.exception(f"An error occurred: {e}")Deploy the Streamlit App on Railway
Railway is a modern app hosting platform that makes it easy to deploy production-ready apps quickly. Sign up for an account using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the LangChain Apps one-click starter template (or click the button below) to deploy the app instantly on Railway.

This template deploys several services - search, text/news/URL summaries, document summary (this one), and generative Q&A. We are deploying from a monorepo, but the root directory has been set accordingly. Accept the defaults and click Deploy; the deployment will kick off immediately.
Once the deployment completes, the Streamlit apps will be available at default xxx.up.railway.app domains - launch each URL to access the respective app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.
Provide the OpenAI API key, upload the source document to be summarized, and click Summarize. Assuming your key is valid, the summary will be displayed in just a few seconds. If you don't have an OpenAI API key, you can get it here.
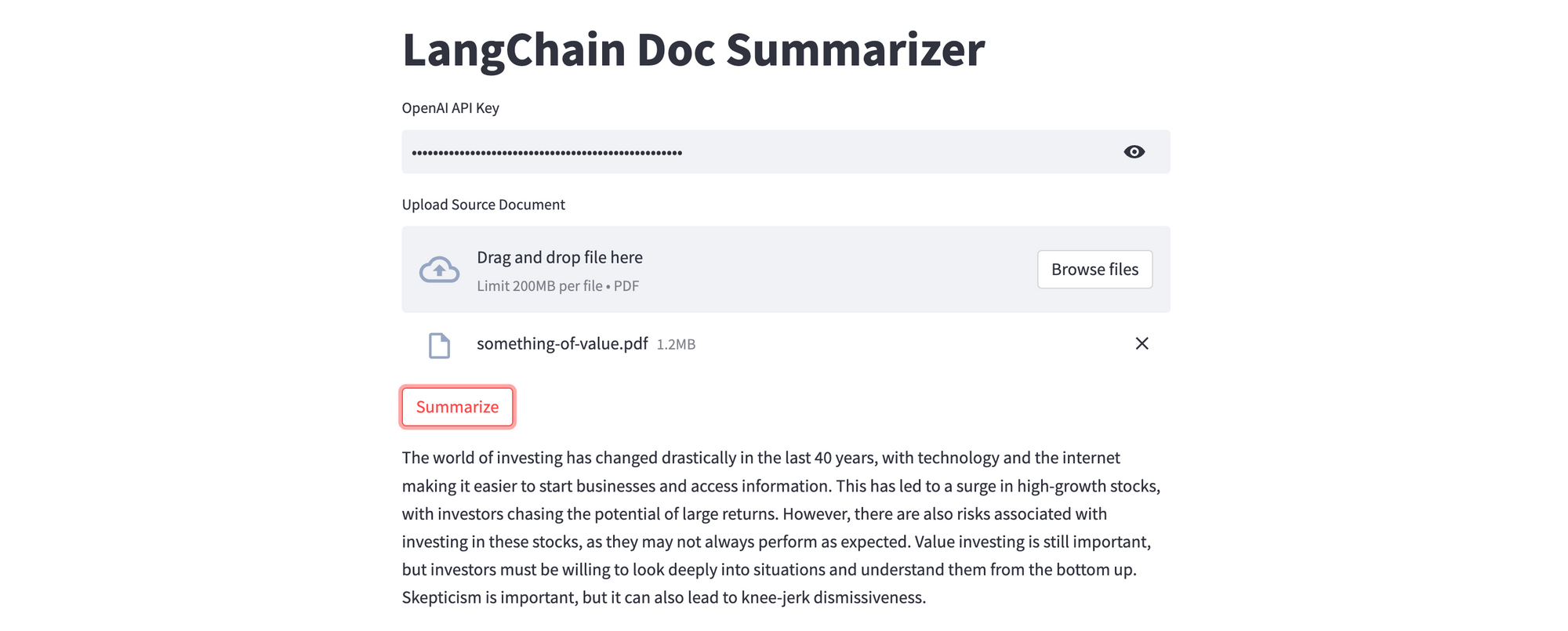
This example uses a fairly simple prompt; you can create a much better summary (e.g. introduction, bullet points), and also define the amount of text to be displayed (here, 150 words), with appropriate changes to the prompt on chain execution. To run Chroma in a persistent mode, pass the directory where you want the data to be save (i.e. chroma_db) when initialising the Chroma client.
Run the Python Notebook with Google Colab
Google Colaboratory (Colab for short), is a cloud-based platform for data analysis and machine learning. It provides a free Jupyter notebook environment that allows users to write and execute Python code in their web browser, with no setup or configuration required. Fork the GitHub repository, or launch the notebook directly in Google Colab using the one-click button below. Click on the play button next to each cell to execute the code within it. Once all the cells execute successfully, the Streamlit app will be available on a ***.loca.lt URL - click to launch the app and play with it.
