Query Your Own Documents with LlamaIndex and LangChain
A brief guide to indexing and querying your own documents using LlamaIndex and LangChain.
In previous posts, I kick-started my large language models (LLM) exploration journey with simple and persistent-memory chatbots. LLMs are phenomenal, but if you want to extend the pre-trained corpus of knowledge, you need to insert context or fine-tune the models. In this post, we'll explore the former i.e. in-context learning using LlamaIndex for data ingestion and indexing.
What is LlamaIndex?
LlamaIndex (previously called GPT Index) is an open-source project that provides a simple interface between LLMs and external data sources like APIs, PDFs, SQL etc. It provides indices over structured and unstructured data, helping to abstract away the differences across data sources. It can store context required for prompt engineering, deal with limitations when the context window is too big, and help make a trade-off between cost and performance during queries.
LllamaIndex offers distinct data structures in the form of purpose-built indices:
- Vector store index: most commonly used, allows you to answer a query over a large corpus of data.
- Tree index: useful for summarising a collection of documents.
- List index: useful for synthesising an answer that combines information across multiple data sources.
- Keyword table index: useful for routing queries to disparate data sources.
- Structured store index: useful for structured data e.g. SQL queries.
- Knowledge graph index: useful for building a knowledge graph.
LlamaIndex also offers data connectors through the LlamaHub, an open-source repository for a variety of data loaders like local directory, Notion, Google Docs, Slack, Discord and more.
What is LangChain?
LangChain is an open-source library created to aid the development of applications leveraging the power of LLMs. It can be used for chatbots, text summarisation, data generation, question answering, and more. See this post for a deep dive into AI chat bots using LangChain. LlamaIndex uses LangChain's LLM and LLMChain modules to define the underlying abstractions, and query indices.
What is Streamlit?
Streamlit is an open-source Python library that allows you to create and share interactive web apps and data visualisations in Python with ease. It includes built-in support for several data visualisation libraries like matplotlib, pandas, and plotly, making it easy to create interactive charts and graphs that update in real-time based on user input. See this post for a deep dive into building interactive Python web apps with Streamlit. I'll use Streamlit to design the user interface.
Use LlamaIndex to Index and Query Your Documents
Let's create a simple index.py file for this tutorial with the code below. We'll use the paul_graham_essay.txt file from the examples folder of the LlamaIndex Github repository as the document to be indexed and queried. You can also replace this file with your own document, or extend the code and seek a file input from the user instead. You'll find my complete code here.
In the sample code below, we load and index the documents from the data folder using a simple vector store index, and then query the index for the information requested by the user. For the frontend, we use Streamlit to create a simple question submission field, with the ability to dynamically update the form with the response. We use the text-davinci-003 model by default, but you can replace it.
import os, streamlit as st
# Uncomment to specify your OpenAI API key here (local testing only, not in production!), or add corresponding environment variable (recommended)
# os.environ['OPENAI_API_KEY']= ""
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader, LLMPredictor, PromptHelper, ServiceContext
from langchain.llms.openai import OpenAI
# Define a simple Streamlit app
st.title("Ask Llama")
query = st.text_input("What would you like to ask? (source: data/paul_graham_essay.txt)", "")
# If the 'Submit' button is clicked
if st.button("Submit"):
if not query.strip():
st.error(f"Please provide the search query.")
else:
try:
# This example uses text-davinci-003 by default; feel free to change if desired
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
# Configure prompt parameters and initialise helper
max_input_size = 4096
num_output = 256
max_chunk_overlap = 20
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
# Load documents from the 'data' directory
documents = SimpleDirectoryReader('data').load_data()
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
response = index.query(query)
st.success(response)
except Exception as e:
st.error(f"An error occurred: {e}")Feel free to deploy the app locally, or on a web hosting platform of your choice. For this walkthrough, I'll use Railway.
Deploy the Streamlit App on Railway
Let's deploy the Streamlit app on Railway, a modern app hosting platform. If you don't already have an account, sign up using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Deploy your forked repository, or simply use the LlamaIndex one-click starter template (or click the button below) to deploy the app instantly.

Review the settings and click Deploy; the deployment will kick off immediately.
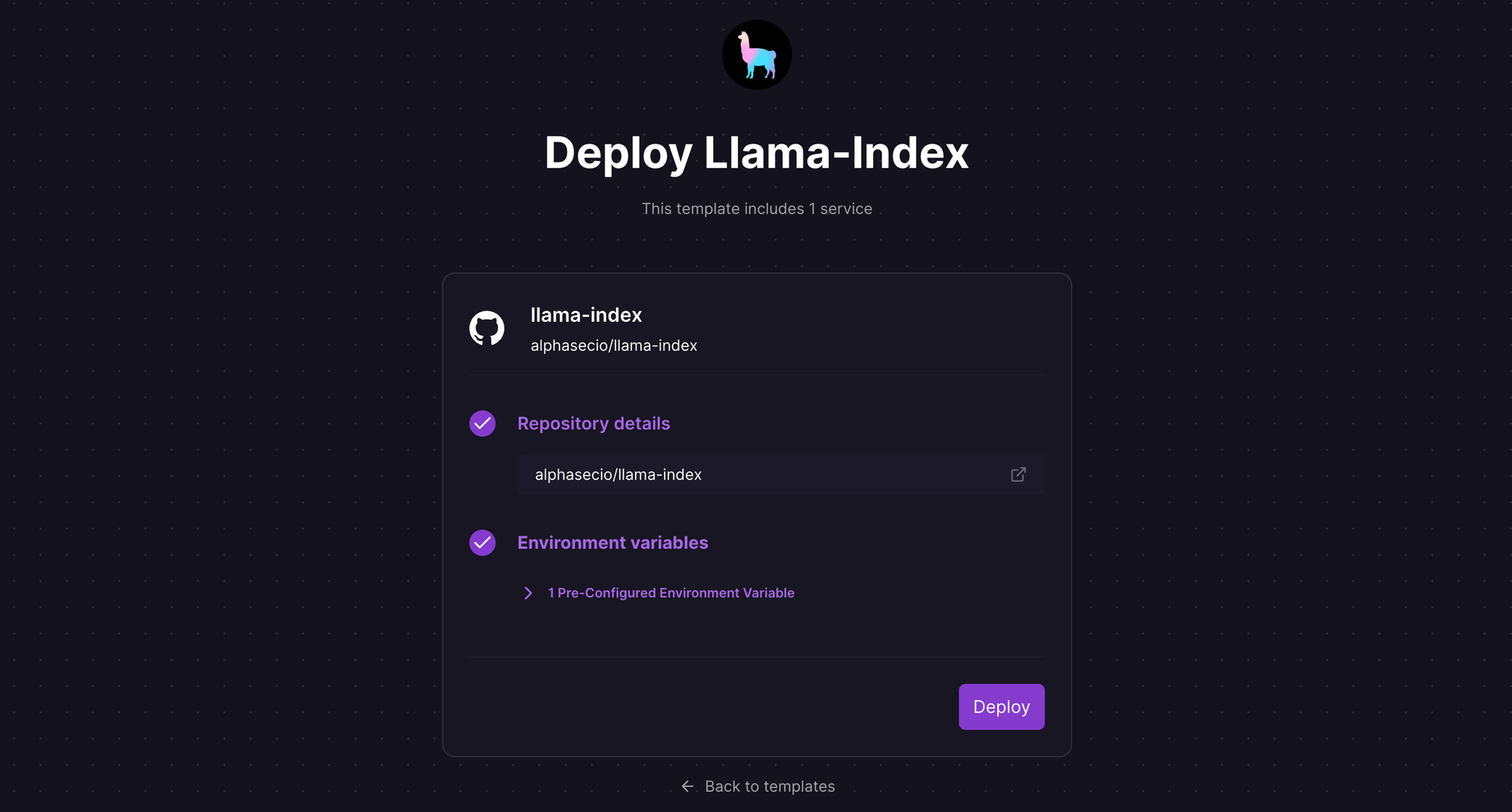
Once the deployment completes, the "Ask Llama" app will be available at a default xxx.up.railway.app domain - launch this URL to access the app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.

Since we are using Paul Graham's 'What I Worked On' essay as the data source here, asking questions pertaining to Paul's life yields concise and fairly accurate results. Frankly, it is tempting to test the code with a whole bunch of questions but, if you aren't prudent, you could raise your OpenAI bill pretty quickly.
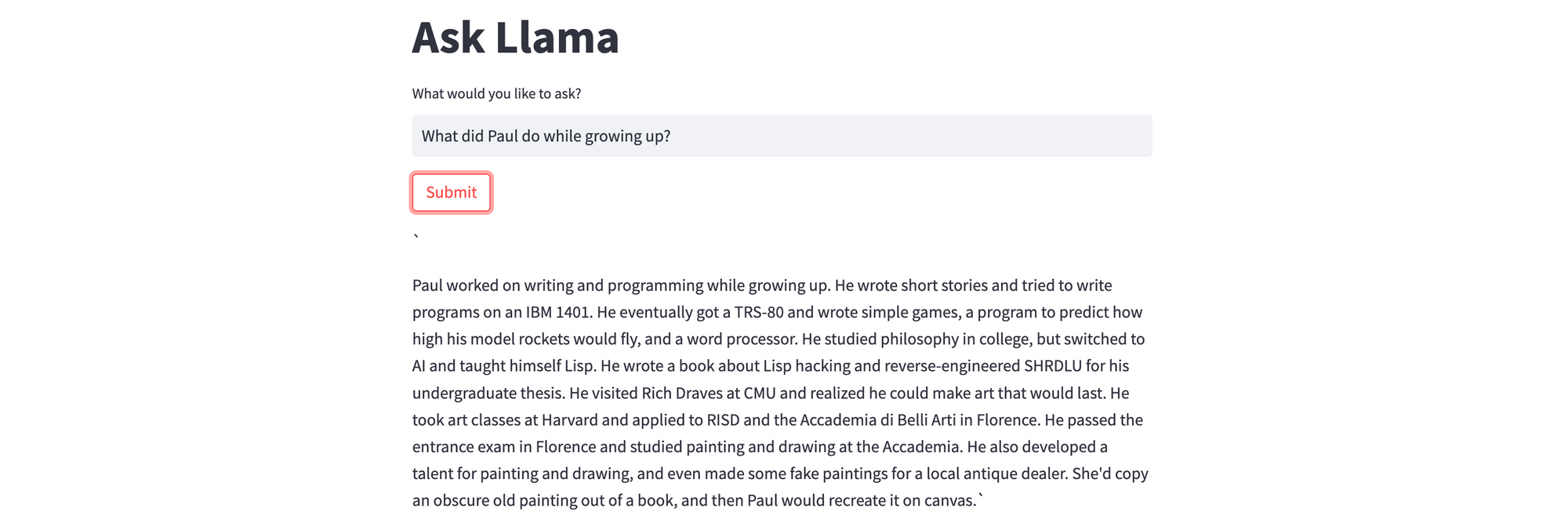
This was definitely a fun exploration for me, and a step up from the question-answer chat bot from my previous post. But I'm also cognisant that I've barely scratched the surface of this gigantic beast that we've unleashed, and I look forward to more rabbit holes.