Generative Question-Answering with LangChain and Pinecone
A brief guide to generative question-answering with LangChain LLM framework and Pinecone vector database.
In previous posts, I have talked extensively about LangChain embeddings, vector stores, and offered a detailed walkthrough of document summarization using Chroma, an open-source vector database. This time, I'll explore generative question-answering with Pinecone, a fully managed alternative.
What is Pinecone?
LangChain is an open-source framework created to aid the development of applications leveraging the power of large language models (LLMs). It can be used for chatbots, text summarisation, data generation, code understanding, question answering, evaluation, and more. Pinecone, on the other hand, is a fully managed vector database, making it easy to build high-performance vector search applications without infrastructure hassles. Once you have generated the vector embeddings using a service like OpenAI Embeddings, you can store, manage and search through them in Pinecone to power semantic search, recommendations, anomaly detection, and other information retrieval use cases. See this post on LangChain Embeddings for a primer on embeddings and sample use cases.
Sign up for an account with Pinecone, or log in if you already have an account, and create an API key. Note the key and environment values.
From the docs, "an index is the highest-level organizational unit of vector data in Pinecone. It accepts and stores vectors, serves queries over the vectors it contains, and does other vector operations over its contents. Each index runs on at least one pod, which are pre-configured units of hardware for running a Pinecone service." With the free Starter plan, you can create one pod with enough resources to support 100K vectors with 1536-dimensional embeddings and metadata.
Click Create your first Index, provide the Index Name and Dimensions, select the Pod Type, and click Create Index.
The index will take a few seconds to initialize; once ready, you can use it in your LangChain app for vector embeddings.
Build a Streamlit App with LangChain and Pinecone
Streamlit is an open-source Python library that allows you to create and share interactive web apps and data visualisations in Python with ease. I'll use Streamlit to create a simple app that allows users to upload a document along with a few necessary parameters, and ask questions pertaining to the document. This app uses PyPDFLoader to load the PDF document, OpenAI to generate embeddings, Pinecone to store the vector embeddings, and LangChain to orchestrate the information retrieval and response generation.
Here's an excerpt from the streamlit_app.py file - you can find the complete source code on GitHub. Note that this is just proof-of-concept code; it has not been developed or optimized for production usage.
import os, tempfile, streamlit as st
from langchain_pinecone import PineconeVectorStore
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import PyPDFLoader
# Streamlit app
st.subheader("Generative Q&A with LangChain & Pinecone")
# Sidebar for settings and source file upload
with st.sidebar:
st.subheader("Settings")
openai_api_key = st.text_input("OpenAI API key", type="password")
pinecone_api_key = st.text_input("Pinecone API key", type="password")
pinecone_index = st.text_input("Pinecone index name")
source_doc = st.file_uploader("Source document", type="pdf")
query = st.text_input("Enter your query")
# Set environment variables for API keys
os.environ['OPENAI_API_KEY'] = openai_api_key
os.environ['PINECONE_API_KEY'] = pinecone_api_key
# Session state initialization for documents and retrievers
if 'retriever' not in st.session_state or 'loaded_doc' not in st.session_state:
st.session_state.retriever = None
st.session_state.loaded_doc = None
submit = st.button("Submit")
if submit:
# Validate inputs
if not openai_api_key or not pinecone_api_key or not pinecone_index or not source_doc or not query:
st.warning(f"Please upload the document and provide the missing fields.")
else:
# Check if it's the same document; if not or if retriever isn't set, reload and recompute
if st.session_state.loaded_doc != source_doc:
try:
# Save uploaded file temporarily to disk, load and split the file into pages, delete temp file
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(source_doc.read())
loader = PyPDFLoader(tmp_file.name)
pages = loader.load_and_split()
os.unlink(tmp_file.name)
# Generate embeddings for the pages, insert into Pinecone vector database, and expose the index in a retriever interface
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = PineconeVectorStore.from_documents(pages, embeddings, index_name=pinecone_index)
st.session_state.retriever = vectorstore.as_retriever()
# Store the uploaded file in session state to prevent reloading
st.session_state.loaded_doc = source_doc
except Exception as e:
st.error(f"An error occurred: {e}")
try:
# Initialize the OpenAI module, load and run the Retrieval Q&A chain
llm = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)
qa = RetrievalQA.from_chain_type(llm, chain_type="stuff", retriever=st.session_state.retriever)
response = qa.run(query)
st.success(response)
except Exception as e:
st.error(f"An error occurred: {e}")Deploy the Streamlit App on Railway
Railway is a modern app hosting platform that makes it easy to deploy production-ready apps quickly. Sign up for an account using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the Pinecone one-click starter template (or click the button below) to deploy the app instantly on Railway.

This template actually deploys two services - one for question-answering, and the other for document summarization. For each, you'll be given an opportunity to change the default repository name and set it private, if you'd like. Accept the defaults and click Deploy; the deployment will kick off immediately.
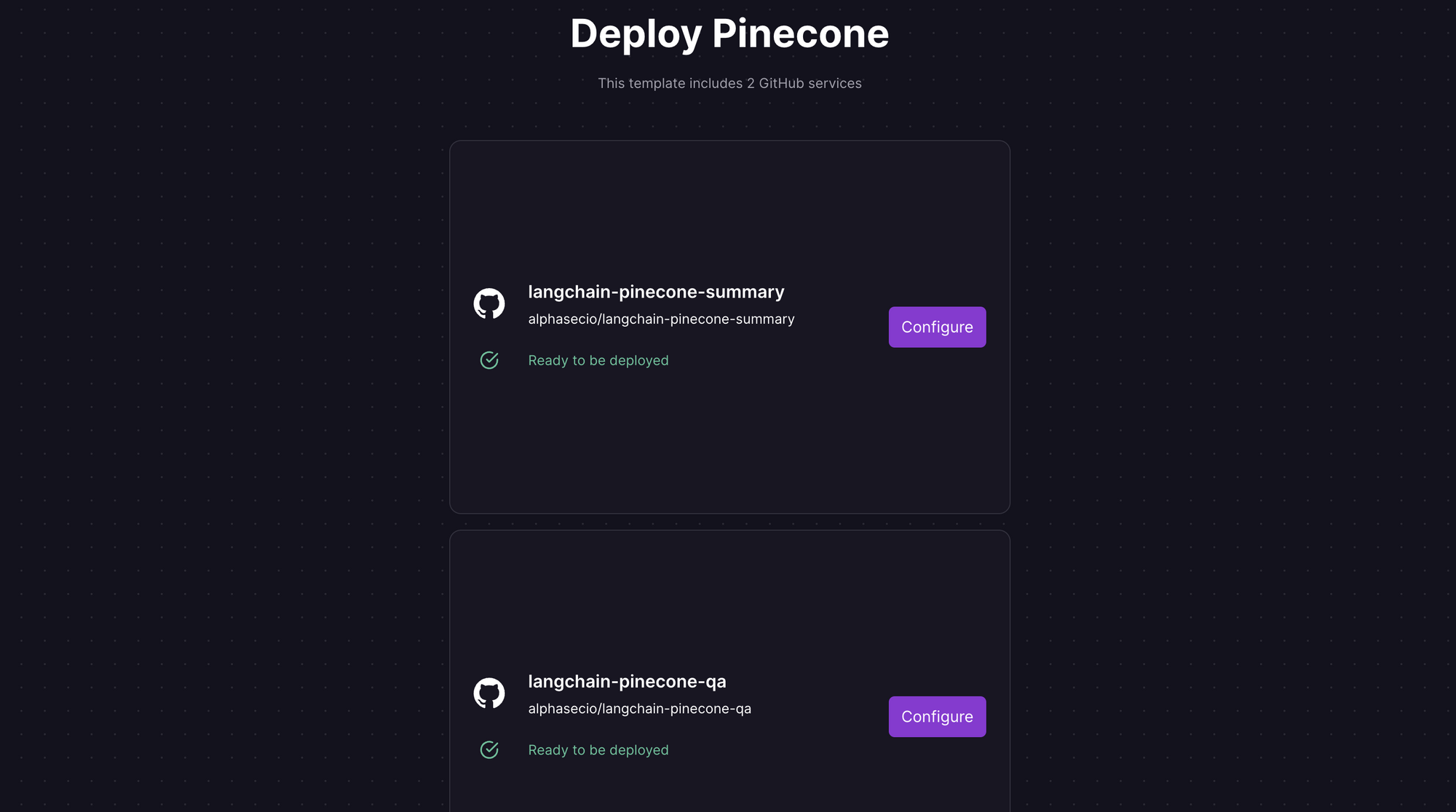
Once the deployment completes, the Streamlit apps will be available at default xxx.up.railway.app domains - launch each URL to access the respective app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.
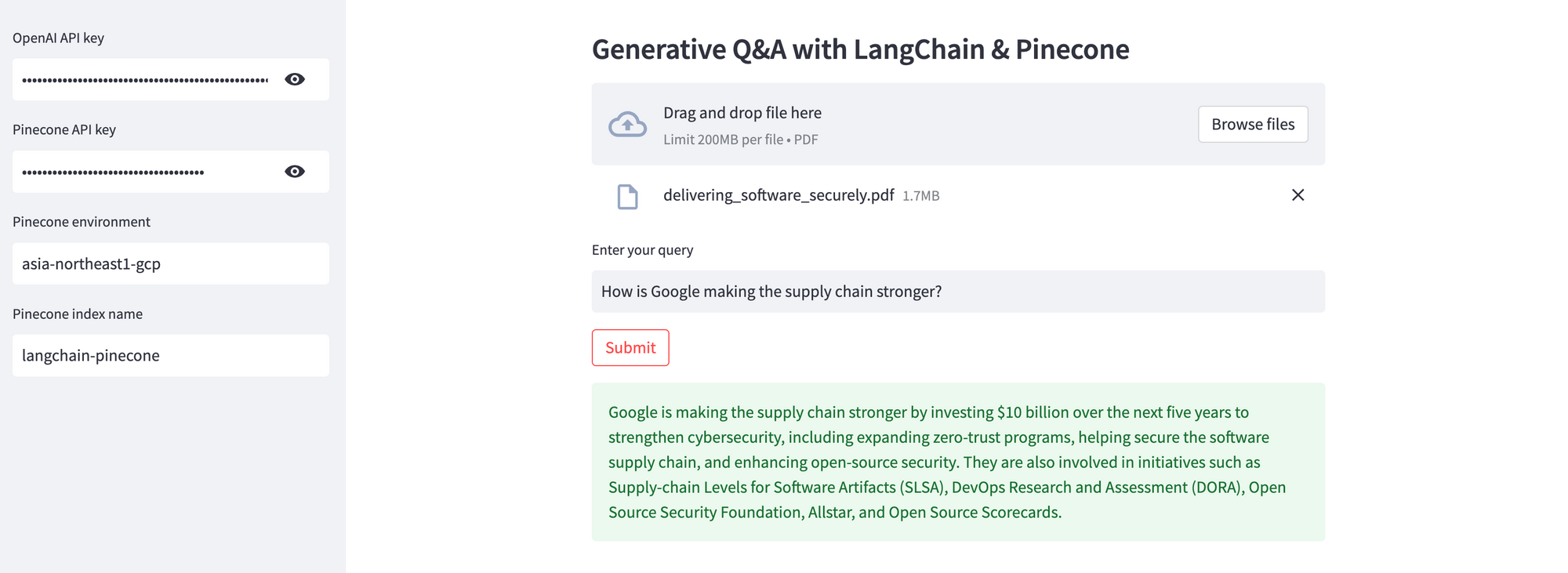
Provide the OpenAI and Pinecone API keys, the Pinecone environment and index name, upload the source document to be queried, enter your query, and click Submit. In the example below, I'll use the Google Cloud white paper on delivering software securely. Assuming your keys are valid, the response will be displayed in just a few seconds. If you don't have an OpenAI API key, you can get it here.
Pinecone is an easy yet highly scalable vector database for your semantic search and information retrieval use cases. And I hope this tutorial showed you just that. Next up, document summarization using LangChain and Pinecone.