Generative Q&A with LangChain, Gemini and Chroma
A step-by-step guide on generative question-answering with LangChain, Gemini and Chroma.
In earlier posts, we explored different use cases with LangChain, including generative question-answering with Pinecone and document summarisation with Chroma. In both cases, we used OpenAI models as our base - today, let's explore Gemini, the latest in generative AI technologies from Google.
What is Gemini?
Gemini is a series of multimodal generative artificial intelligence (AI) models developed by Google, available in Pro, Ultra, Nano and Flash sizes. Gemini models can accept text and image in prompts, depending on the model variation you choose, and output text responses. You can access Gemini API via the Google AI Studio, or via Google's flagship Vertex AI machine learning platform. We'll use the former for this walkthrough, so, sign up for an account and get an API key first.
PS: If you're looking for inspiration, head over to the prompt gallery for ideas on creating a good Gemini prompt, or review the API cookbook for more details.
Build a Streamlit App with LangChain, Gemini and Chroma
LangChain is an open-source framework created to aid the development of applications leveraging the power of large language models (LLMs). It can be used for chatbots, text summarisation, data generation, code understanding, question answering, evaluation, and more. Chroma, on the other hand, is an open-source, lightweight embedding (or vector) database that can be used to store embeddings locally. Together, developers can easily and quickly create AI-native applications.
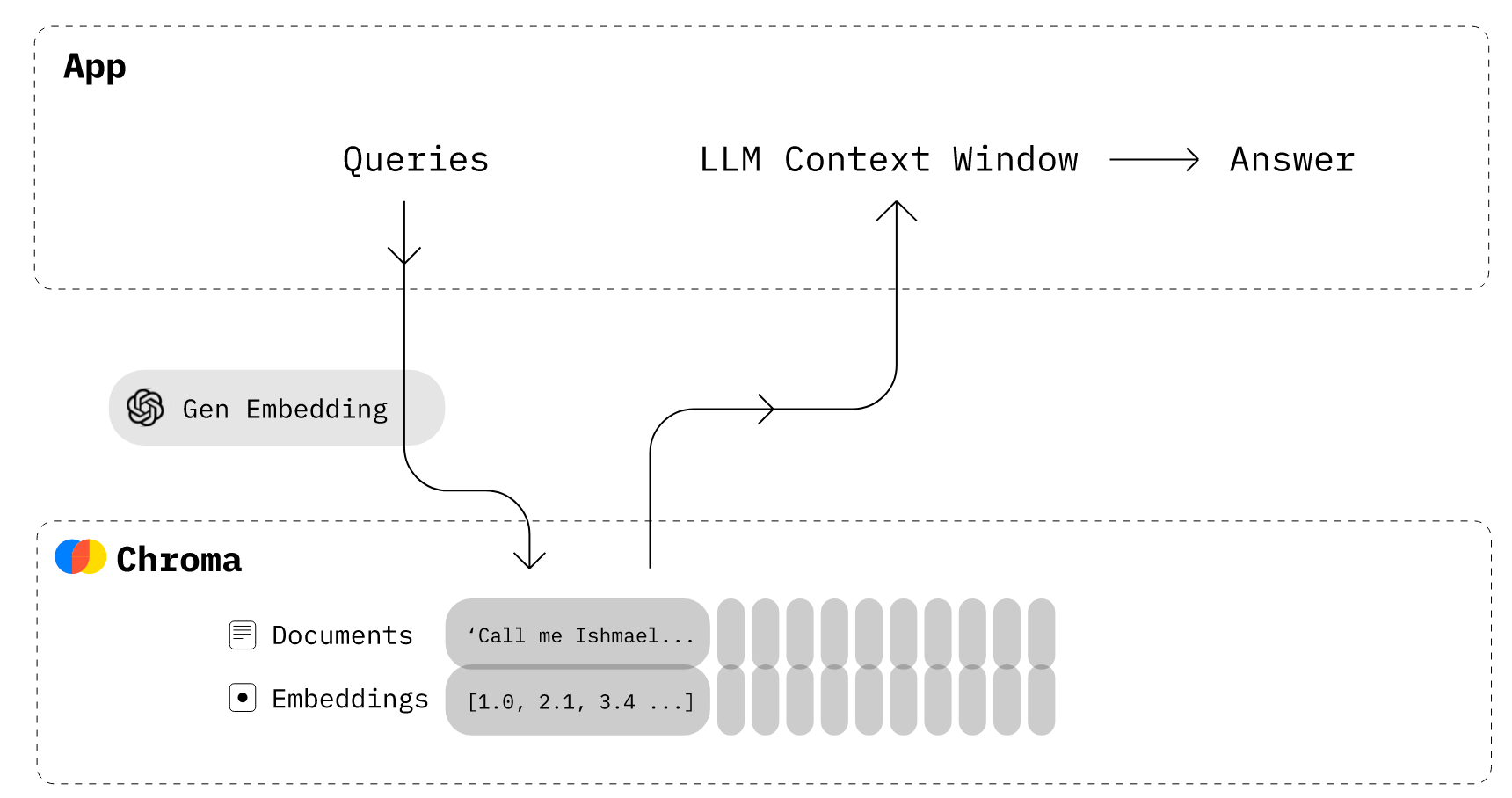
To chat with a PDF document, we first split the uploaded file into individual pages, create embeddings for each page using the Google embeddings API, and insert them into the Chroma vector database. Then, we retrieve the information from the vector database using a similarity search, and run the LangChain Chains module to return the appropriate response.
Google's gemini-pro model is optimised for text-only input, while the gemini-pro-vision model is optimised for text-and-image input. Gemini also allows you to have freeform conversations across multiple turns - the ChatSession class manages the state of the conversation, eliminating the need to store conversation history as a list. Gemini models have default safety settings which can block messages if they violate the LLM safety checks. If you get empty responses, you can try to tweak the safety_settings attribute and override the defaults.
Here's the streamlit_app.py file for a simple "Chat with PDF" use case (without Chroma persistence) - you can find the complete source code on GitHub.
import os, tempfile, streamlit as st
from langchain.prompts import PromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain_chroma import Chroma
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
# Streamlit app config
st.subheader("Generative Q&A with LangChain, Gemini and Chroma")
with st.sidebar:
google_api_key = st.text_input("Google API key", type="password")
source_doc = st.file_uploader("Source document", type="pdf")
col1, col2 = st.columns([4,1])
query = col1.text_input("Query", label_visibility="collapsed")
os.environ['GOOGLE_API_KEY'] = google_api_key
# Session state initialization for documents and retrievers
if 'retriever' not in st.session_state or 'loaded_doc' not in st.session_state:
st.session_state.retriever = None
st.session_state.loaded_doc = None
submit = col2.button("Submit")
if submit:
# Validate inputs
if not google_api_key or not query:
st.warning("Please provide the missing fields.")
elif not source_doc:
st.warning("Please upload the source document.")
else:
with st.spinner("Please wait..."):
# Check if it's the same document; if not or if retriever isn't set, reload and recompute
if st.session_state.loaded_doc != source_doc:
try:
# Save uploaded file temporarily to disk, load and split the file into pages, delete temp file
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(source_doc.read())
loader = PyPDFLoader(tmp_file.name)
pages = loader.load_and_split()
os.remove(tmp_file.name)
# Generate embeddings for the pages, and store in Chroma vector database
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
vectorstore = Chroma.from_documents(pages, embeddings)
#Configure Chroma as a retriever with top_k=5
st.session_state.retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# Store the uploaded file in session state to prevent reloading
st.session_state.loaded_doc = source_doc
except Exception as e:
st.error(f"An error occurred: {e}")
try:
# Initialize the ChatGoogleGenerativeAI module, create and invoke the retrieval chain
llm = ChatGoogleGenerativeAI(model="gemini-pro")
template = """
You are a helpful AI assistant. Answer based on the context provided.
context: {context}
input: {input}
answer:
"""
prompt = PromptTemplate.from_template(template)
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(st.session_state.retriever, combine_docs_chain)
response = retrieval_chain.invoke({"input": query})
st.success(response['answer'])
except Exception as e:
st.error(f"An error occurred: {e}")Deploy the Streamlit App on Railway
Railway is a modern app hosting platform that makes it easy to deploy production-ready apps quickly. Sign up for an account using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the LangChain Apps one-click starter template (or click the button below) to deploy the app instantly on Railway.

This template deploys several services - search, text/document/news summaries, URL summary, and generative Q&A (this one). We are deploying from a monorepo, but the root directory has been set accordingly. Accept the defaults and click Deploy; the deployment will kick off immediately.
Once the deployment completes, the Streamlit apps will be available at default xxx.up.railway.app domains - launch each URL to access the respective app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.
When the Streamlit app is ready, provide the Google API key, upload the source document, and ask away! In the example below, I uploaded Alphabet's latest quarterly earnings report, and asked for specific information from the filing.
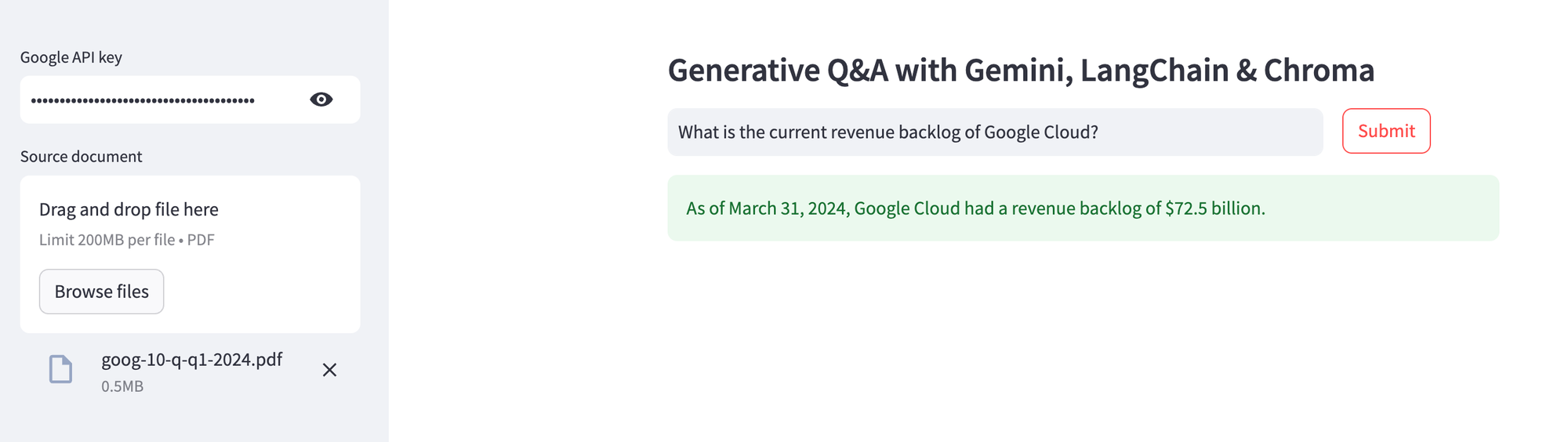
As you can see from the source document (snippet) below, the information retrieved is indeed accurate. Upload different PDF documents, and enjoy your very own "Chat with PDF" capability!
