Open-Source LLM Observability with Helicone
A brief on observability challenges for large language models (LLMs), and how to address them using the open-source platform Helicone.
As the demand for large language models (LLMs) grows rapidly, and developers start building LLM-powered generative AI applications, the need for observability and maintainability grows hand-in-hand. Ensuring the quality of the prompts used to generate responses is a key challenge, which can impact the accuracy and relevance of the model's output. Additionally, optimizing for speed and cost-effectiveness while still maintaining high levels of performance can be a delicate balancing act. In this blog post, we'll discuss an open-source observability platform, Helicone, which offers pretty good insights into LLM usage and metrics.
Build an LLM Observability App with Streamlit and Helicone
LangChain is an open-source framework created to aid the development of applications leveraging the power of large language models (LLMs). It can be used for chatbots, text summarisation, data generation, code understanding, question answering, evaluation, and more. Helicone, on the other hand, is an open-source observability platform for tracking costs, usage, and latency for LLM-powered applications. It proxies OpenAI traffic (for now, other LLM providers in the future), and provides key usage metrics and insights.
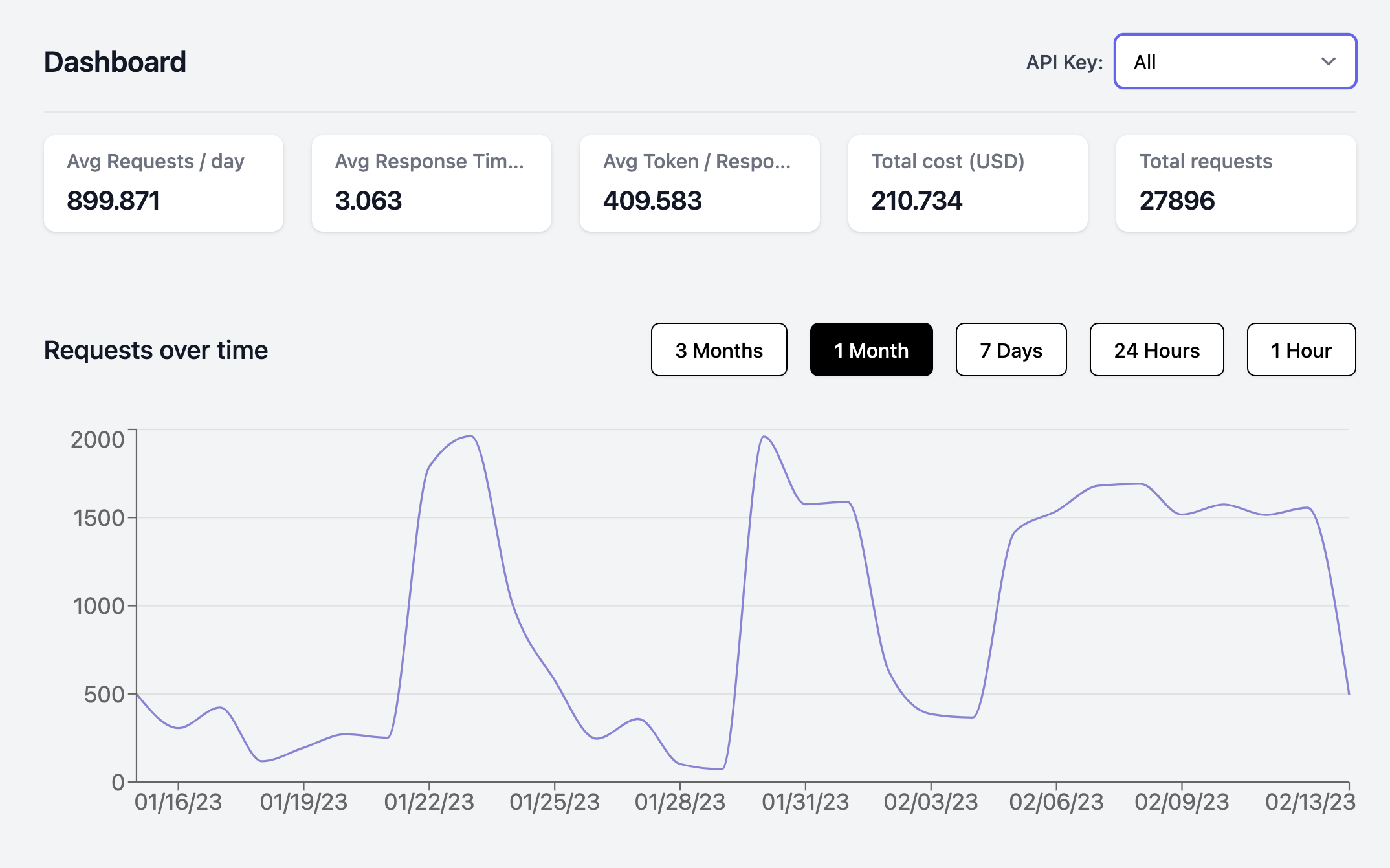
Helicone tracks and displays the usage, latency, and costs of your LLM requests. It is easy to integrate with, and can visualize metrics by requests, users, and models. It also helps you understand latency variations and rate limits, and bill users accurately according to their API usage.
Helicone runs on Cloudflare, and uses Workers for low latency and efficient web traffic routing globally. Helicone also uses Cloudflare cache control to ensure fast cache hits, if configured. Because Helicone is open-source, you can deploy the proxy workers in your own environment, or use the Helicone cloud solution. The steps to self-host Helicone are covered here; I'll use the cloud option for this guide.
Here's an excerpt from the streamlit_app.py file - you can find the complete source code on GitHub.
import streamlit as st
from langchain_openai import OpenAI
# Streamlit app
st.subheader('LLM Observability with Helicone')
# Get OpenAI API key, Helicone API key, and user query
with st.sidebar:
openai_api_key = st.text_input("OpenAI API Key", type="password")
helicone_api_key = st.text_input("Helicone API Key", type="password")
user_query = st.text_input("Your Query")
# If the 'Submit' button is clicked
if st.button("Submit"):
# Validate inputs
if not openai_api_key.strip() or not helicone_api_key.strip() or not user_query.strip():
st.error(f"Please provide the missing fields.")
else:
try:
with st.spinner('Please wait...'):
# Initialize OpenAI model with Helicone integration
llm = OpenAI(
temperature=0.9,
openai_api_key=openai_api_key,
base_url="https://oai.hconeai.com/v1",
default_headers={
"Helicone-Auth": f"Bearer {helicone_api_key}",
"Helicone-Cache-Enabled": "true"
}
)
# Run user query and display response
st.success(llm(user_query))
except Exception as e:
st.error(f"An error occurred: {e}")Deploy the Streamlit App on Railway
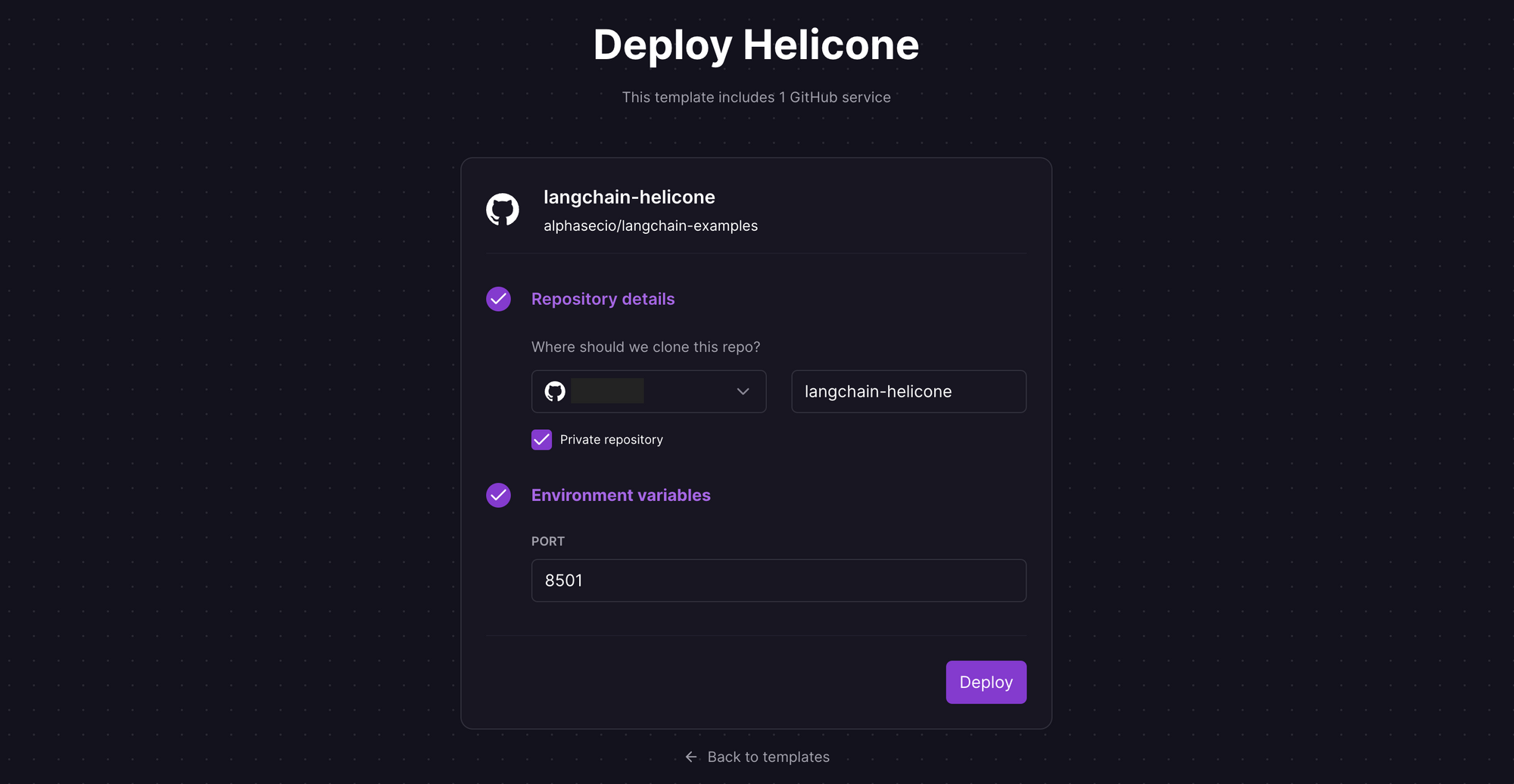
Railway is a modern app hosting platform that makes it easy to deploy production-ready apps quickly. Sign up for an account using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the Helicone one-click starter template (or click the button below) to deploy the app instantly on Railway.

You'll be given an opportunity to change the default repository name and set it private, if you'd like. Accept the defaults and click Deploy; the deployment will kick off immediately.
Once the deployment completes, the Streamlit app will be available at a default xxx.up.railway.app domain - launch this URL to access the app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.
Observe Model Usage Metrics & Insights in Helicone
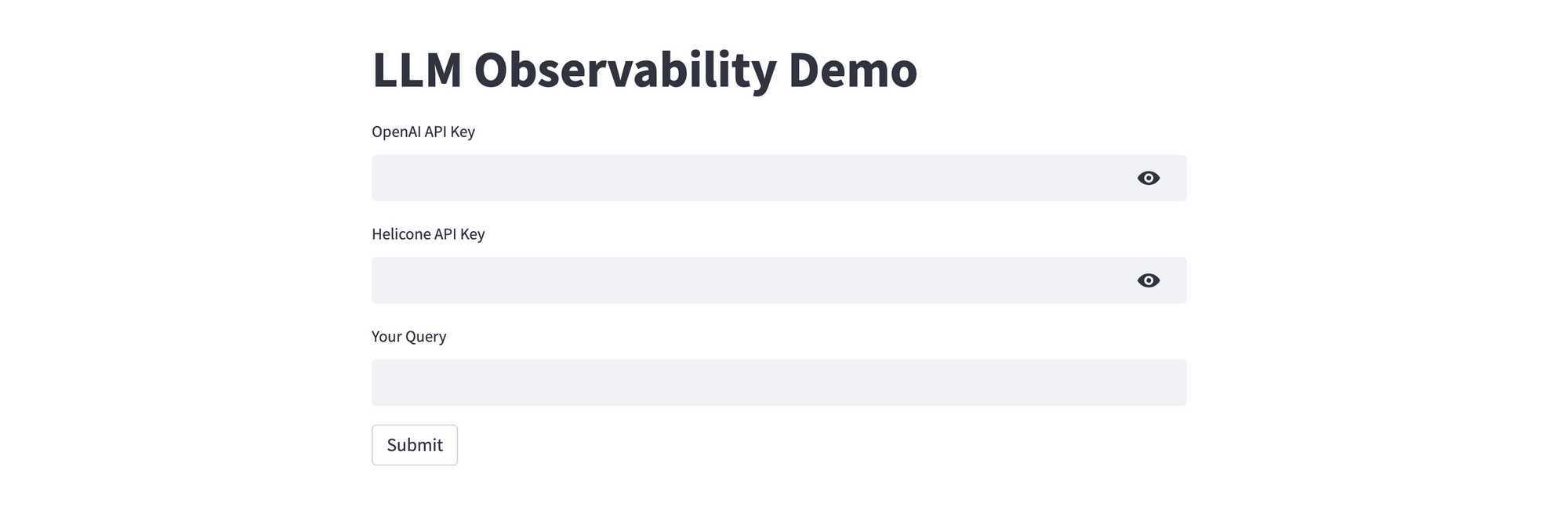
To get started, sign up for an account with Helicone. You will be asked to generate an API key, and be offered a few code samples for integrating Helicone with your app. Since our app already includes this code, Helicone is ready to listen to events.

In your app, provide the OpenAI and Helicone API keys, ask your query, and click Submit. Assuming your keys are valid, the response will be displayed in just a few seconds. If you don't have an OpenAI API key, you can get it here.

Switch back to the Helicone dashboard - you'll now see the requests come through. Make a few more requests to generate additional Helicone data.
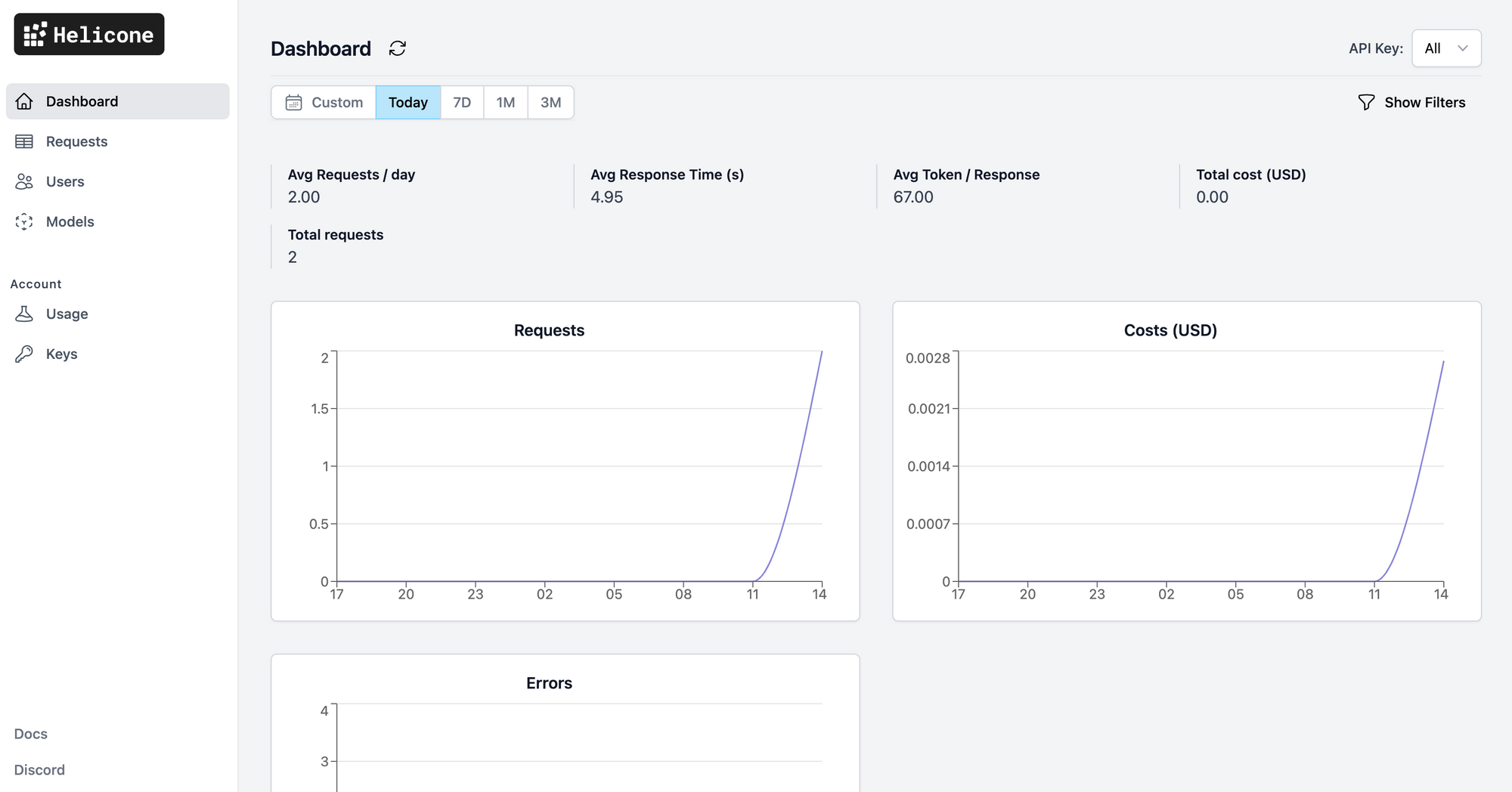
Helicone tracks and displays the usage, latency, and costs of your LLM requests. The Requests tab shows both Condensed and Expanded versions of the requests - drilling into the requests shows additional information, including the raw JSON request and response data.
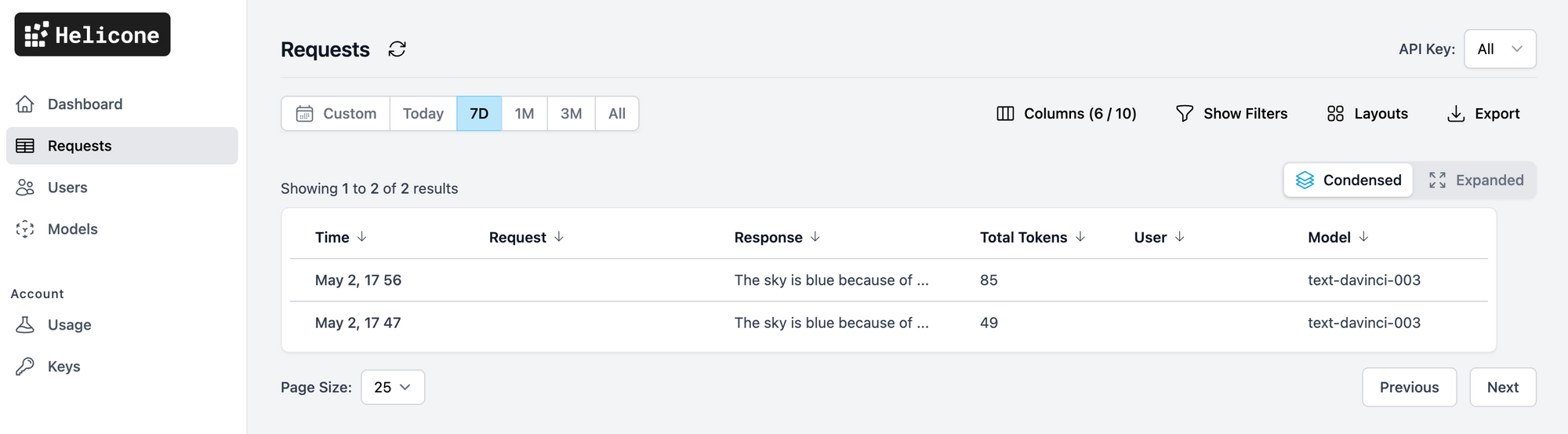
The Models tab shows model metrics, including the token usage and costs. Optionally, the OpenAI API also allows you to track requests per user - if configured, the user metadata will be populated in the Users tab.

You can also define and tag requests with custom properties (e.g. session, conversation, application), allowing you to segment, analyze, and visualize usage metrics based on those properties. Add the respective Helicone-Property-{Name} key-value pair to the headers attribute when making the request. Helicone is a fairly nascent solution, and I expect it to grow rapidly in the months to come.
Run the Python Notebook with Google Colab
Google Colaboratory (Colab for short), is a cloud-based platform for data analysis and machine learning. It provides a free Jupyter notebook environment that allows users to write and execute Python code in their web browser, with no setup or configuration required. Fork the GitHub repository, or launch the notebook directly in Google Colab using the button below. Click the play button next to each cell to execute the code. Once all cells execute successfully, the Streamlit app will be available on a ***.loca.lt URL - click to launch the app and play with it.
