Getting Started with Google Cloud Vertex AI PaLM API
A brief guide to getting started with Google Cloud Vertex AI PaLM API, including samples for question-answering and text summarization.
Since the launch of ChatGPT late last year, the death of Google has been greatly exaggerated. At the just concluded Google I/O event, artificial intelligence (AI) clearly took centre-stage, and Google dazzled with generative AI capabilities embedded inside all its core products, including Search.
One of the highlights was PaLM 2, Google's next-generation large language model (LLM), which has an improved model architecture and excels at advanced reasoning tasks like code and math, text classification, question answering, translation, and natural language generation better than previous LLMs including PaLM. PaLM 2 was evaluated rigorously for harms and biases, and is being used in other state-of-the-art (SOTA) models like Med-PaLM 2 and Sec-PaLM. It also powers Google Bard, MakerSuite, and the PaLM API. In this post, I'll explore use cases like question-answering and text summarization, and build a simple Streamlit app to play with it.
Disclaimer: This is not an officially supported Google or Google Cloud project; it is a personal project created for educational and experimental purposes.
What is Google Cloud Vertex AI PaLM API?
I know, it's a mouthful. Vertex AI is Google Cloud's fully-managed platform for building, deploying, and scaling machine learning models. The Vertex AI PaLM API allows you to build and deploy generative AI applications using PaLM 2. It offers foundation models for text generation, chat, and text embeddings. You can interact with PaLM API using the Generative AI Studio, cURL commands in Cloud Shell, or using the Python SDK in a Jupyter notebook. This post only focuses on the Python SDK; see this if you want to get started with the UI instead.
The models follow the naming convention: <use-case>-<model-size>@<version-number>. Gecko is the smallest and cheapest model for simple tasks, while Bison offers the best value in terms of capability and cost. Following models are currently supported by the PaLM API:
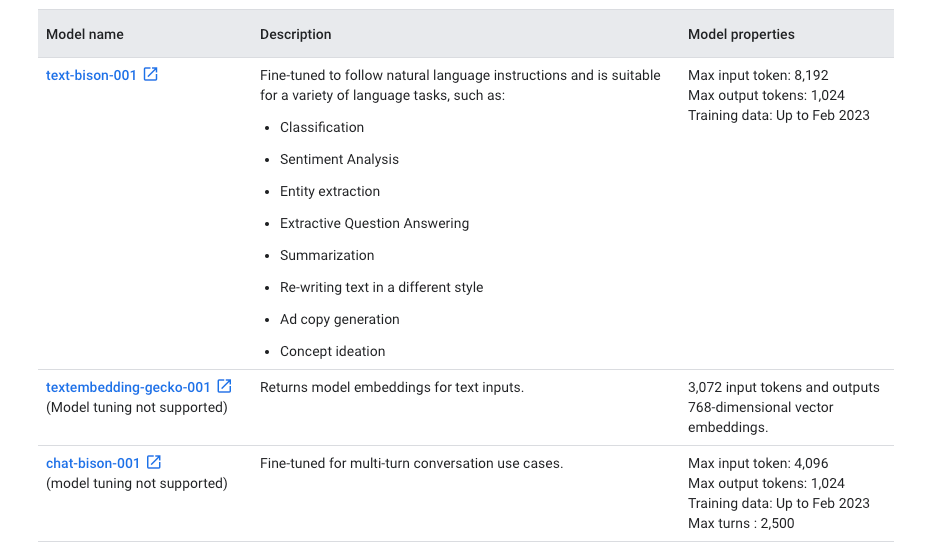
In addition, it is important to understand the nuances of model parameters like temperature, max_output_tokens, top_k, and top_p, and how each parameter can affect the output.
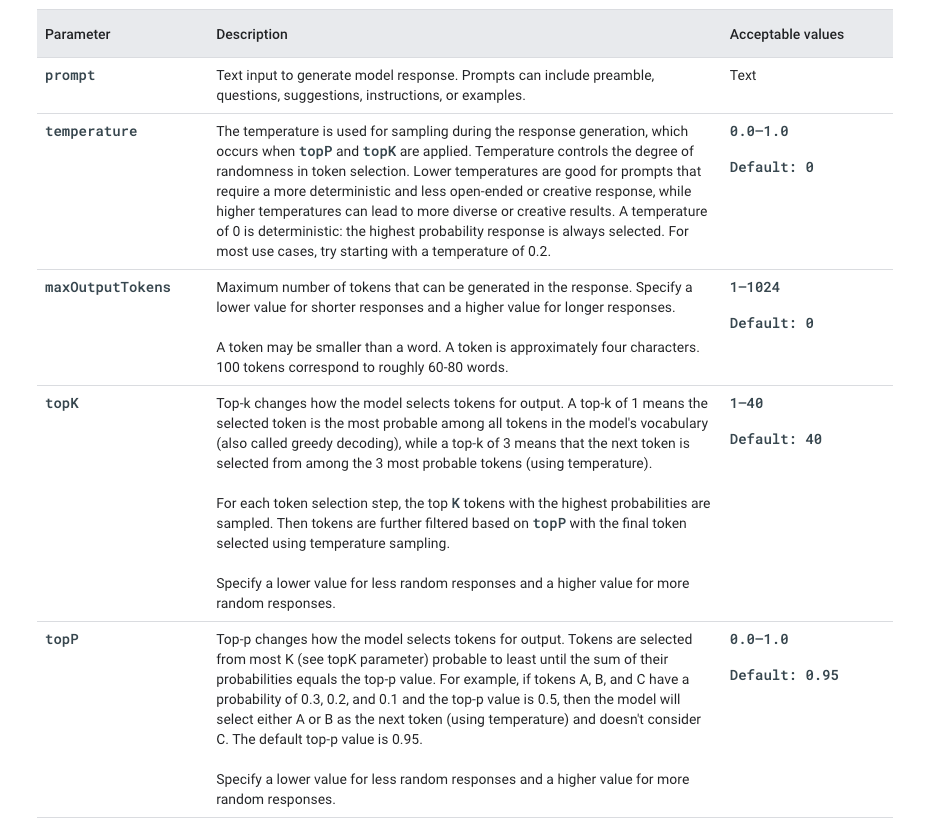
PaLM APIs are charged by model based on the character length of each input and output; see this for more details. For PaLM APIs to get adopted across Enterprise organizations, privacy and data commitments are critical; in this regard, Google asserts that it does not log customer data, allow employees to see the submissions, or use the customer data to improve its foundation models.
For this tutorial, you'll need a Google Cloud account, and a project with the Vertex AI API enabled. If you don't already have an account, sign up here - new customers get a generous $300 credit for 90 days, with several always-free products once the trial period expires. From the Google Cloud Console, enable billing on your account, create a new project (note the project ID), and do the following:
- Navigate to
Artificial Intelligence>Vertex AI>Dashboard, and enable theVertex AI API. - Optionally, if you want to run the Streamlit app on Railway, navigate to
APIs & Services>Enabled APIs & services, and selectVertex AI APIfrom the list. From theCredentialstab, clickCreate Credentials>Service account, and create a service account with theVertex AI Userrole. Finally, add and download a new key for this service account i.e. JSON credentials file.
Set Up Google Colab and Authenticate to Google Cloud
Google Colaboratory (Colab for short), is a cloud-based platform for data analysis and machine learning. It provides a free Jupyter notebook environment that allows users to write and execute Python code in their web browser, with no setup or configuration required. Create a new notebook and follow along the rest of this tutorial, or click the Open in Colab button below to launch the consolidated notebook directly in Colab. Click the play button next to each cell to execute the code. Once all cells execute successfully, the Streamlit app will be available on a ***.loca.lt URL - click to launch the app and play with it.

Install Streamlit as well as the latest Google Cloud AI Platform Python SDK - this metapackage includes the Vertex AI libraries. Once the packages are installed, you'll be asked to Restart Runtime - click on the button to restart the runtime.
!pip install streamlit
!pip install --upgrade google-cloud-aiplatformNext, authenticate your Colab environment with your Google Cloud account. The account you use must have access to the project where Vertex AI API was enabled.
from google.colab import auth
auth.authenticate_user()When you get a popup asking you to Allow this notebook to access your Google credentials?, click Allow to continue. In the following section, we'll walk through two common use cases - question-answering, and text summarization.
Question Answering with PaLM API
In this section, we'll explore question-answering with PaLM API. Similar to other LLM providers like OpenAI, you can use zero-shot prompts, few-shot prompts, and provide additional domain knowledge as context to the PaLM API. Good prompts are specific, descriptive, offer context and helpful information, cite examples, and provide guidance about the desired output/format/style etc.
Here's an excerpt from my streamlit_app.py file. Provide the Google Cloud project ID and location (region) as arguments when you initialize Vertex AI. This notebook shows a simple zero-shot prompt example using the text-bison@001 text generation model.
import vertexai, streamlit as st
from vertexai.preview.language_models import TextGenerationModel
# Initialize Vertex AI with the required variables
PROJECT_ID = '' # @param {type:"string"}
LOCATION = '' # @param {type:"string"}
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Streamlit app
st.title('Palmfish')
prompt = st.text_input("Your Query")
if st.button("Submit"):
if not prompt.strip():
st.write(f"Please submit your query.")
else:
try:
model = TextGenerationModel.from_pretrained("text-bison@001")
response = model.predict(
prompt,
temperature=0.1,
max_output_tokens=256
)
st.success(response)
except Exception as e:
st.error(f"An error occurred: {e}")You can use few-shot prompts to provide examples of expected responses to the model. Here is an example taken from the Google Cloud docs for illustration. The docs also provide examples for adding internal knowledge as context in prompts, instruction-tuning outputs, evaluating outputs, and more.
prompt = """Q: Who is the current President of France?\n
A: Emmanuel Macron \n\n
Q: Who invented the telephone? \n
A: Alexander Graham Bell \n\n
Q: Who wrote the novel "1984"?
A: George Orwell
Q: Who discovered penicillin?
A:
"""
print(generation_model.predict(
prompt,
max_output_tokens=20,
temperature=0.1,
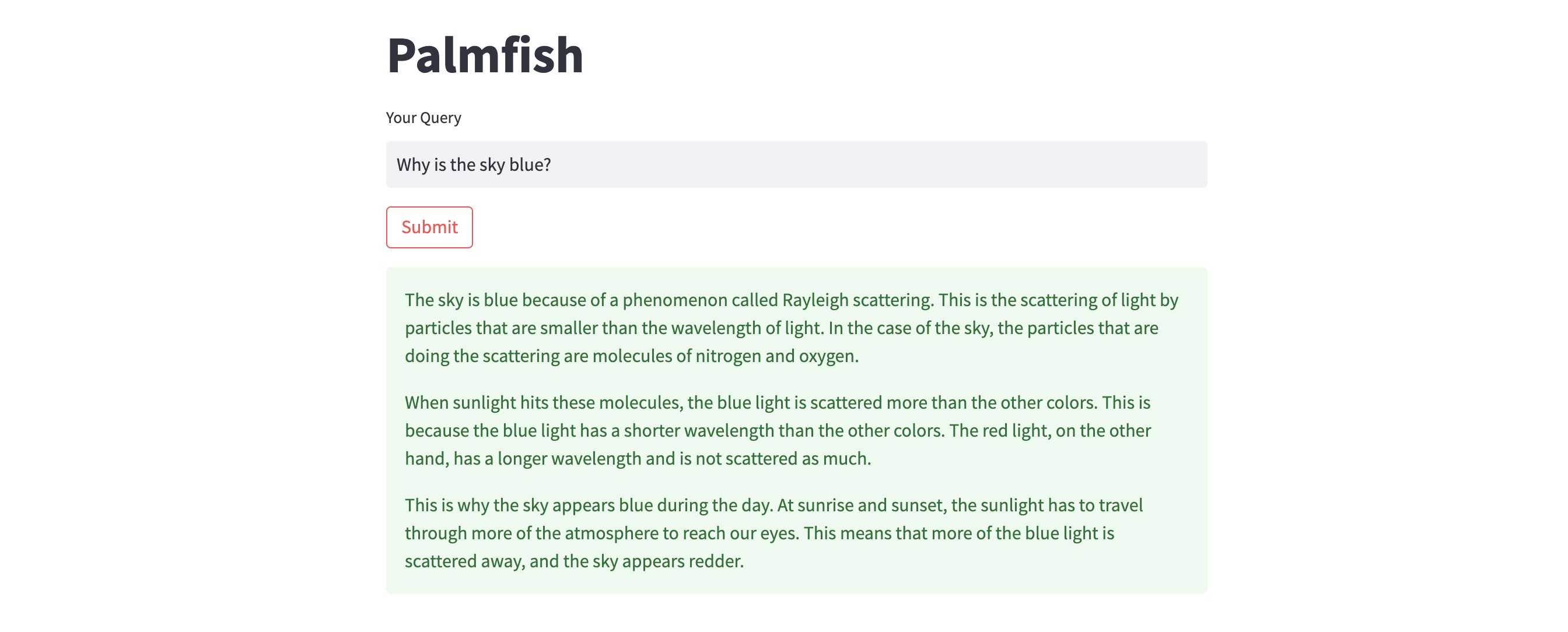
).text)Here's a sample illustration of question-answering with the Streamlit app.
Text Summarization with PaLM API
In this section, we'll explore text summarization with PaLM API. There are two main summarization types - extractive and abstractive. In extractive summarization, critical sentences are selected from the original text, and combined to form a summary. In abstractive summarization, new sentences representing the original text's main points are generated.
Here's an excerpt from my streamlit_app.py file. Provide the Google Cloud project ID and location (region) as arguments when you initialize Vertex AI. This notebook shows a simple summarization example using the text-bison@001 text generation model.
import vertexai, streamlit as st
from vertexai.preview.language_models import TextGenerationModel
# Initialize Vertex AI with the required variables
PROJECT_ID = '' # @param {type:"string"}
LOCATION = '' # @param {type:"string"}
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Streamlit app
st.title('Palmfish')
source_text = st.text_area("Source Text", height=200)
prompt = 'Provide a summary within 250 words for the following article: \n' + source_text + '\nSummary: '
if st.button("Summarize"):
if not source_text.strip():
st.write(f"Please provide the text to summarize.")
else:
try:
model = TextGenerationModel.from_pretrained("text-bison@001")
response = model.predict(
prompt,
temperature=0.2,
max_output_tokens=256,
top_k=40,
top_p=0.8,
)
st.success(response)
except Exception as e:
st.error(f"An error occurred: {e}")You can also ask the model to summarize text in bullet-point form, summarize dialogues, generate titles using appropriate prompts, evaluate outputs, and more. The Google Cloud docs provide several examples for the same.
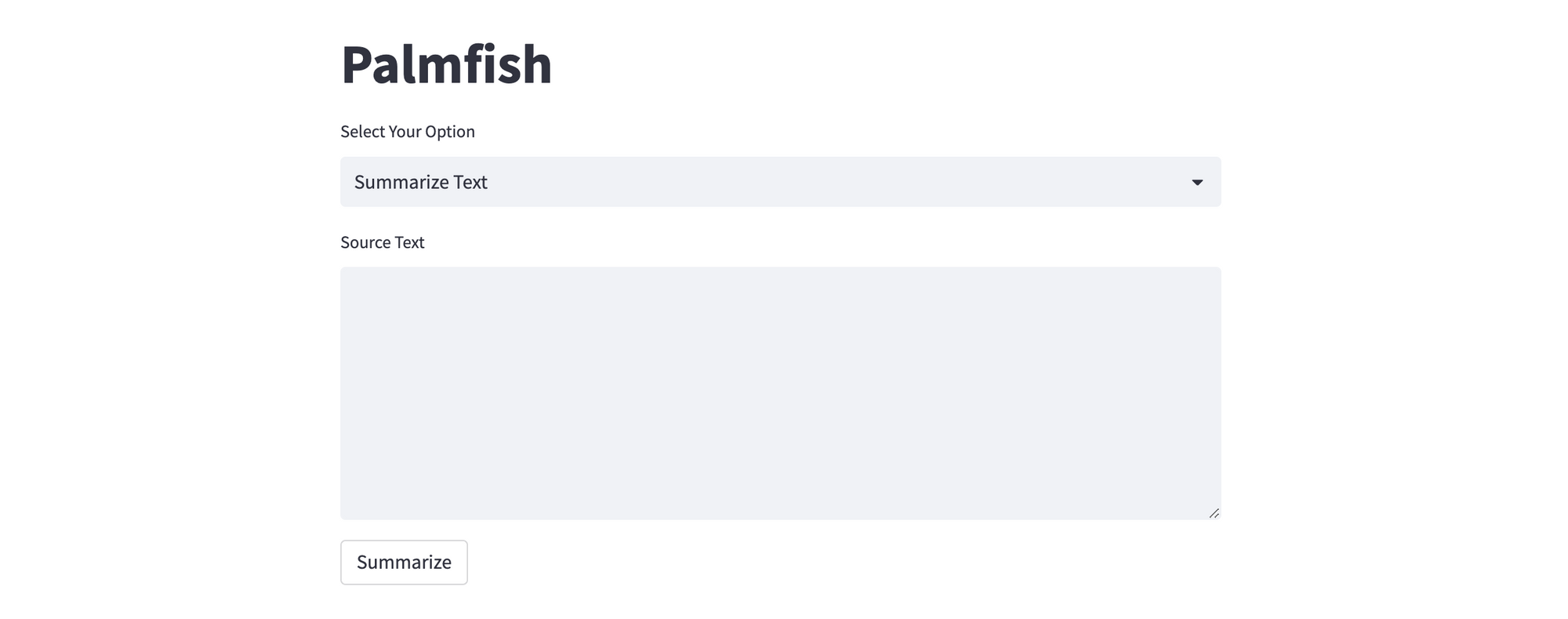
Here's a sample illustration of text summarization with the Streamlit app.

Deploy the Streamlit App on Railway
Railway is a modern app hosting platform that makes it easy to deploy production-ready apps quickly. Sign up for an account using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the Google Cloud Apps one-click starter template (or click the button below) to deploy the app instantly on Railway.

This template deploys several services - Web Risk API, PaLM API (this one), and more. For each, you'll be given an opportunity to change the default repository name and set it private, if you'd like. Accept the defaults and click Deploy; the deployment will kick off immediately.

Once the deployment completes, the Streamlit apps will be available at default xxx.up.railway.app domains - launch each URL to access the respective app. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.

The sample app needs to authenticate to Google Cloud and use the Vertex AI PaLM API - upload the JSON credentials file that you previously downloaded. You can choose between two options - Answer Question and Summarize Text. If you select the former, provide your question and click Submit to get a response generated by the PaLM API. For the latter, provide the source text to be summarized, and click Summarize. In both cases, the max_output_tokens parameter is set to 256.
This post only covers text generation using the foundation model text-bison@001; I encourage you to experiment with other models e.g. chat model chat-bison@001, text embeddings model textembedding-gecko@001, and compare them with the corresponding models available from other LLM providers too.