Magika: Enhancing File Content Type Detection through Deep Learning
Enhancing file content type detection through deep learning with Magika, an open-source tool by Google.
In their latest blog, Google announced that they are open-sourcing Magika, an AI-powered file content type detection tool. Magika uses a lightweight, highly optimized deep learning model that enables precise file type identification within milliseconds, with over 99% accuracy. While file detection is not a new technology, the accuracy, performance, and maintainability of previous libraries like libmagic has been a tricky affair. With AI being increasingly used by bad actors to bypass detection mechanisms, it's good to see an increase in the positive uses of AI too.
Google has been using Magika internally to improve user safety across Gmail, Drive, and Safe Browsing, and has integrated it with their crowdsourced malware intelligence platform, VirusTotal, to augment it's Code Insight capabilities.

Magika is available as a standalone CLI tool, or as a Python/JavaScript package, and supports over 100 content types. You can test Magika using Google's web demo, or integrate with the Magika libraries in your own application.
Try Magika with a Streamlit App
Install the dependencies and run the app locally with pip. Alternatively, if you'd rather not run it locally, you can deploy this app to Railway - just push the code to a GitHub repo and connect it from the Railway dashboard.
pip install magika streamlit
streamlit run streamlit_app.pyHere's the full source for the Streamlit app:
import os, tempfile, mimetypes
import magika, streamlit as st
from pathlib import Path
m = magika.Magika()
# Streamlit app config
st.set_page_config(page_title="Magika Content-Type Scanner")
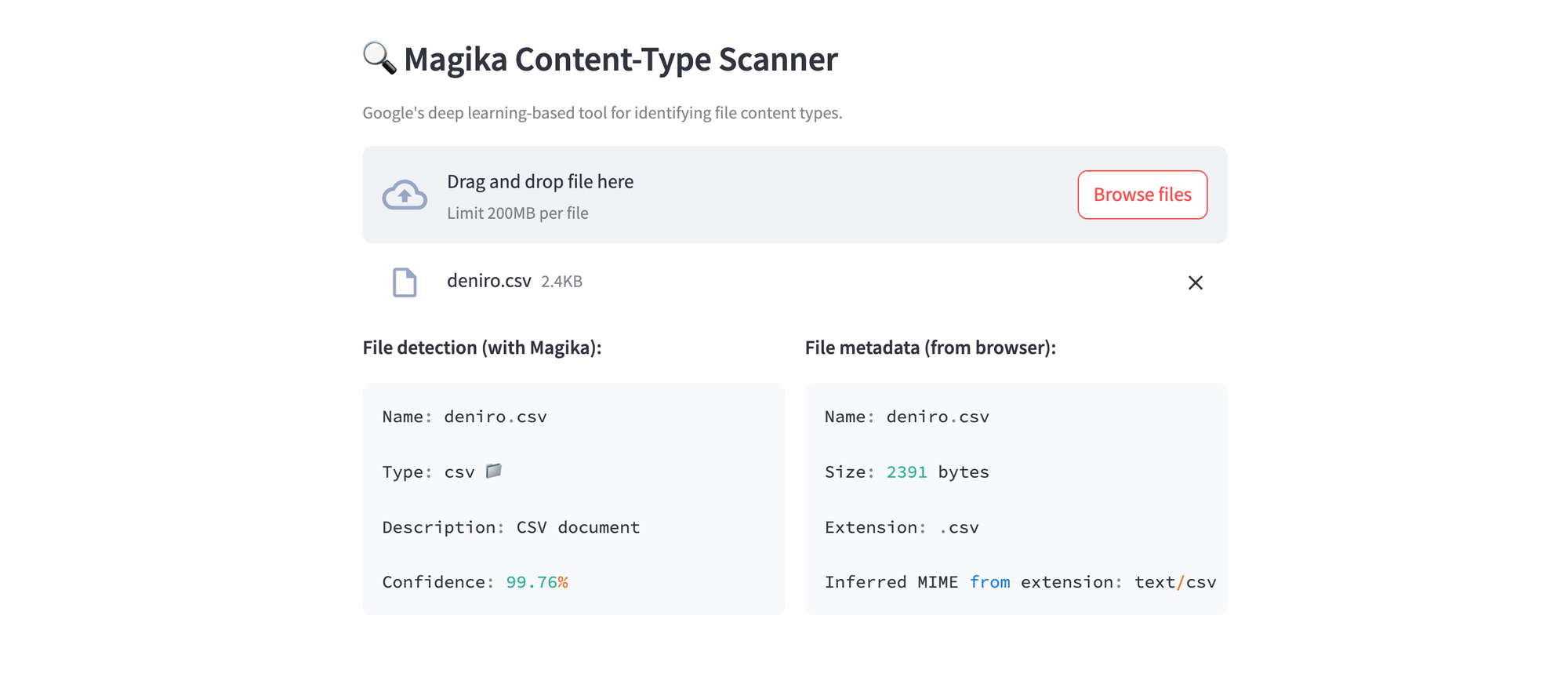
st.subheader("🔍 Magika Content-Type Scanner")
st.caption("Google's deep learning-based tool for identifying file content types.")
source_file = st.file_uploader("Source File", label_visibility="collapsed")
def get_filetype_icon(label):
if "image" in label:
return "🖼️"
elif "script" in label or "code" in label or "text/x" in label:
return "🧾"
elif "pdf" in label or "doc" in label or "text/plain" in label:
return "📄"
elif "audio" in label:
return "🎵"
elif "video" in label:
return "🎞️"
elif "zip" in label or "compressed" in label:
return "📦"
else:
return "📁"
if source_file:
try:
# Save uploaded file temporarily to disk, pass the file path to Magika, delete the temp file
file_bytes = source_file.read()
file_ext = os.path.splitext(source_file.name)[-1].lower().strip(".")
mime_from_ext, _ = mimetypes.guess_type(source_file.name)
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(file_bytes)
result = m.identify_path(Path(tmp_file.name))
if result.ok:
detected_type = result.output.label
description = result.output.description
confidence = "{:.2f}%".format(result.score * 100)
icon = get_filetype_icon(detected_type)
col1, col2 = st.columns(2)
col1.markdown(f"**File detection (with Magika):**")
col1.code(
f"Name: {source_file.name}\n\n"
f"Type: {detected_type} {icon}\n\n"
f"Description: {description}\n\n"
f"Confidence: {confidence}"
)
col2.markdown("**File metadata (from browser):**")
col2.code(
f"Name: {source_file.name}\n\n"
f"Size: {len(file_bytes)} bytes\n\n"
f"Extension: .{file_ext}\n\n"
f"Inferred MIME from extension: {mime_from_ext or 'unknown'}"
)
else:
st.error(f"Magika failed with status: {result.status}")
except Exception as e:
st.exception(f"An error occurred: {e}")
finally:
os.remove(tmp_file.name)The app is intentionally minimal — it tests the default capabilities of the Magika library and compares its deep-learning-based detection against the browser's MIME inference from file extension. For more details on the full API, see the Magika GitHub repo.