Running Open-Source Generative AI Models on Fireworks AI
A brief on running open-source text and image generation models on Fireworks AI.

Since the launch of Llama by Meta, open source generative artificial intelligence (AI) models have gained significant attention due to their ability to generate interesting outputs, such as images, music, and text. These models have been made available under open source licenses, allowing researchers and developers to access, modify, and distribute the code freely. This has led to a further surge in development and hosting of open source models, with many downstream benefits. In this blog post, we will explore how to run open source generative AI models on Fireworks AI, a budding model hosting platform.
What is Fireworks AI?
Fireworks AI is a relatively new platform for building and deploying generative AI models with a cloud API, without having to manage your own infrastructure. While you can run your own models too, Fireworks' claim-to-fame is blazing fast inference for open-source models like Meta Llama, Google Gemma, Mistral, Stable Diffusion, and others. Sign up for an account at Fireworks and get an API key - you'll get $1.00 in credits to test their models. I'll use the Python code samples published by Fireworks, and build a simple model playground using Streamlit. The models used in my app below are maintained by Fireworks, but there are plenty others for you to explore.

Generate Text using Meta Llama 3.3 70B Instruct Model
Meta Llama 3.3 70B Instruct is a 70 billion parameter language model from Meta, pre-trained and fine-tuned for chat completions. It has a context window of 16384 tokens, 4x that of Llama 2, and has advances in tool calling, multilingual text support, math and coding. You can modify the system prompt to guide model responses. The model is currently priced at $0.90 / 1M input and output tokens.

Here's sample Python code to run the llama-v3p3-70b-instruct model using Fireworks API - you'll find the code for my Streamlit app here.
# Run llama-v3p3-70b-instruct model on Fireworks AI
response = fireworks.client.ChatCompletion.create(
model="accounts/fireworks/models/llama-v3p3-8b-instruct",
messages=[{
"role": "user",
"content": prompt,
}],
)Generate Text using Google Gemma 2 9B Instruct Model
Google Gemma 2 9B Instruct is a 9 billion parameter instruction-tuned language model from Google, built from the same research and technology used to create the larger, more powerful Gemini models. The model is currently priced at $0.20 / 1M input and output tokens.

Here's sample Python code to run the gemma2-9b-it model using Fireworks API - you'll find the code for my Streamlit app here.
# Run gemma2-9b-it model on Fireworks AI
response = fireworks.client.ChatCompletion.create(
model="accounts/fireworks/models/gemma2-9b-it",
messages=[{
"role": "user",
"content": prompt,
}],
)Generate Text using Mixtral MoE 8x7B Instruct Model
Mixtral MoE 8x7B Instruct model is a pretrained generative Sparse Mixture of Experts from Mistral, tuned to be a helpful assistant. The model is currently priced at $0.50 / 1M input and output tokens.

Here's sample Python code to run the mixtral-8x7b-instruct model using Fireworks API - you'll find the code for my Streamlit app here.
# Run mixtral-8x7b-instruct model on Fireworks AI
response = fireworks.client.ChatCompletion.create(
model="accounts/fireworks/models/mixtral-8x7b-instruct",
messages=[{
"role": "user",
"content": prompt,
}],
)Generate Text using DeepSeek V3 Model
Since their release, DeepSeek models, particularly R1 and V3, have taken the world by storm. DeepSeek V3 is a strong Mixture-of-Experts (MoE) language model with 671B total parameters and 37B activated for each token. The model is currently priced at $0.90 / 1M input and output tokens.
DeepSeek R1, on the other hand, is a state-of-the-art language model optimised with reinforcement learning and cold-start data for exceptional reasoning, math, and code performance. It is also available in serverless mode on Fireworks AI, and is priced at $8.00 / 1M input and output tokens.
Here's sample Python code to run the deepseek-v3 model using Fireworks API - you'll find the code for my Streamlit app here.
# Run deepseek-v3 model on Fireworks AI
response = fireworks.client.ChatCompletion.create(
model="accounts/fireworks/models/deepseek-v3",
messages=[{
"role": "user",
"content": prompt,
}],
)Generate Text using 01 Yi Large Model
01 Yi Large model is a relatively new entrant, with performance closely trailing GPT-4, Gemini 1.5 Pro, and Claude 3 Opus. It excels in multilingual capabilities, especially in Spanish, Chinese, Japanese, German, and French. The model is currently priced at $3.00 / 1M input and output tokens.
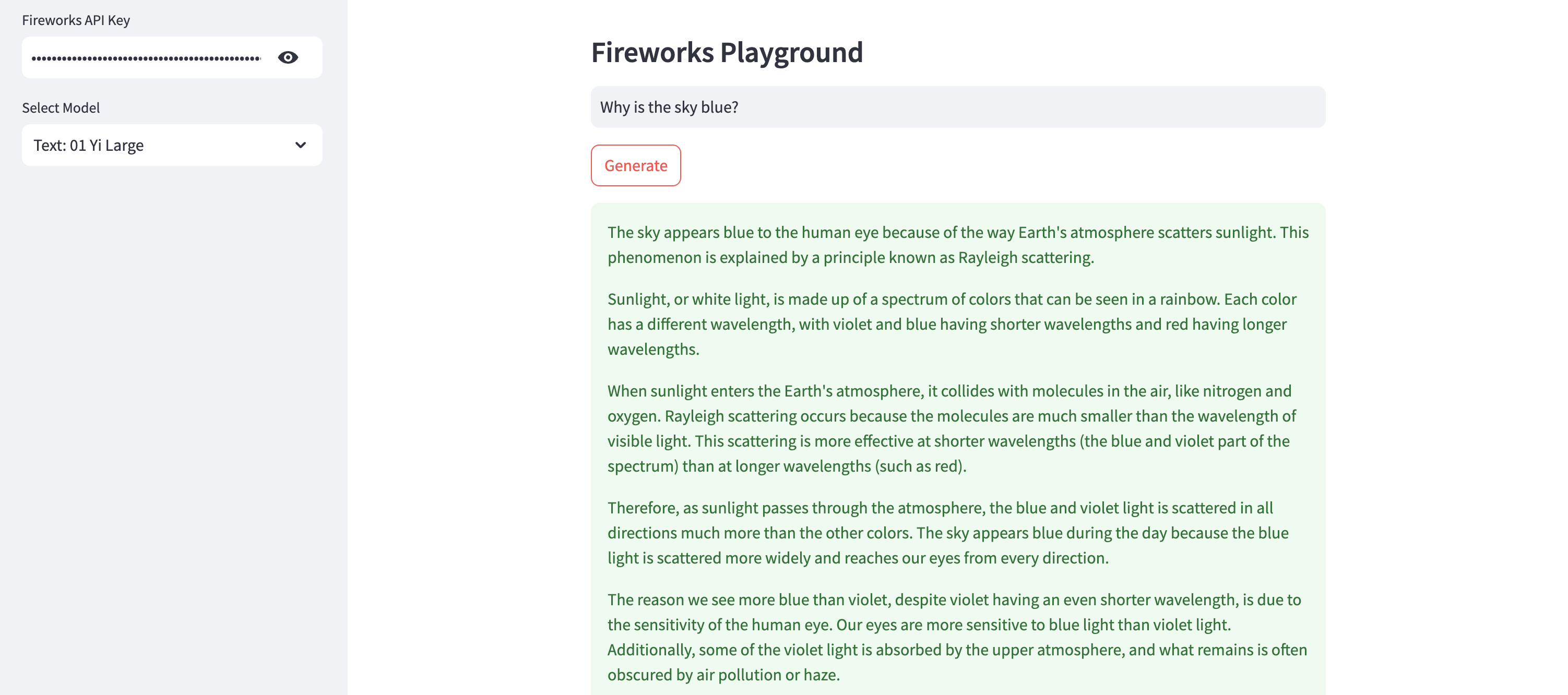
Here's sample Python code to run the yi-large model using Fireworks API - you'll find the code for my Streamlit app here.
# Run yi-large model on Fireworks AI
response = fireworks.client.ChatCompletion.create(
model="accounts/fireworks/models/yi-large",
messages=[{
"role": "user",
"content": prompt,
}],
)Generate Image using Stable Diffusion XL Model
Stable Diffusion XL is a diffusion-based text-to-image generative AI model that creates beautiful images. You can apply a watermark, and enable a safety check for generated images. The model is priced by the number of inference steps (denoising iterations); each step costs $0.00013. So, a 30-step image would cost $0.0039.
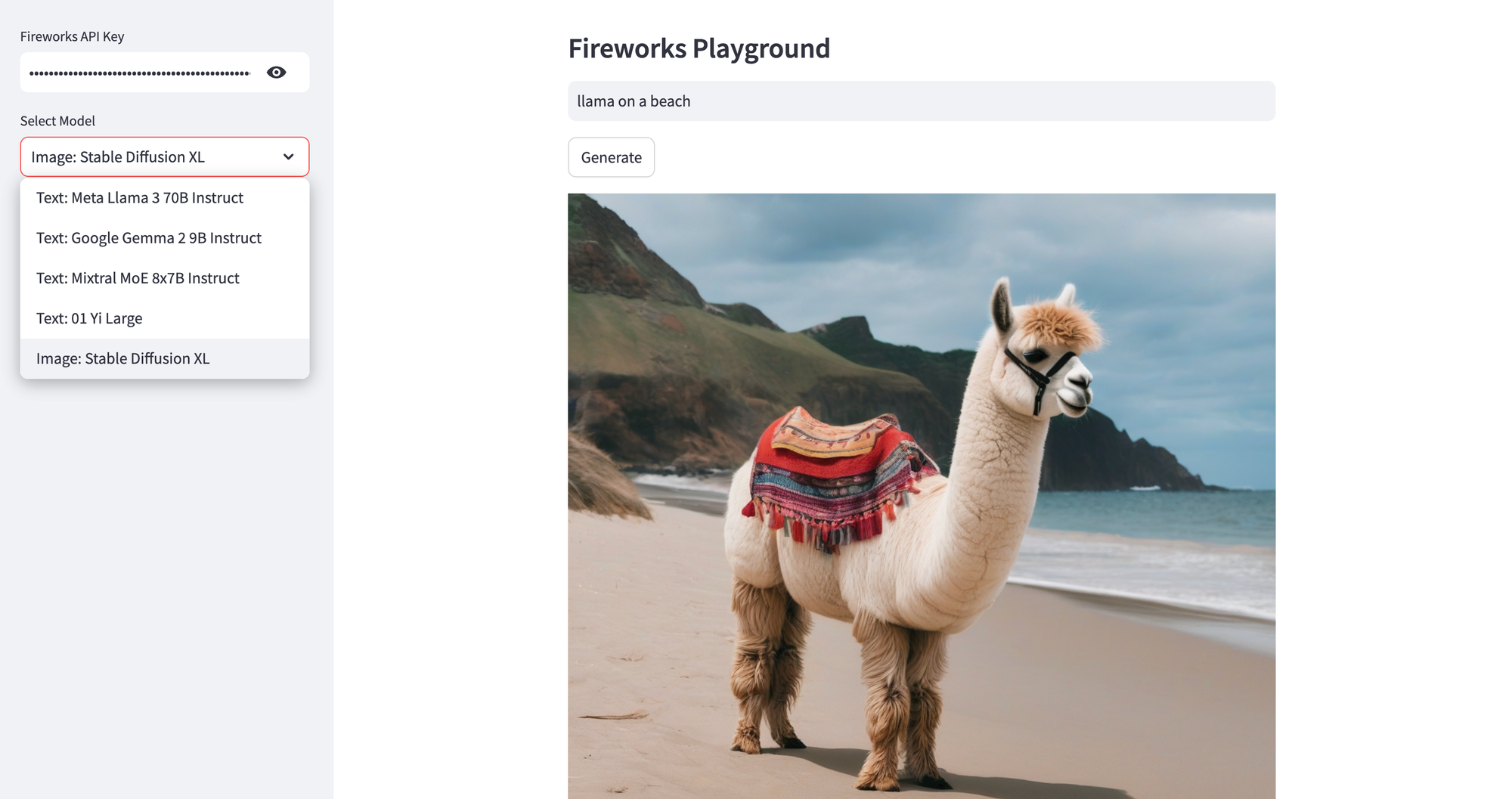
Here's sample Python code to run the stable-diffusion-xl-1024-v1-0 model using Fireworks API - you'll find the code for my Streamlit app here.
# Run stable-diffusion-xl-1024-v1-0 model on Fireworks AI
client = ImageInference(model="stable-diffusion-xl-1024-v1-0")
answer : Answer = client.text_to_image(
prompt=prompt,
cfg_scale=7,
height=1024,
width=1024,
sampler=None,
steps=30,
seed=0,
safety_check=False,
output_image_format="PNG"
)Deploy the Streamlit App on Railway
To test these models, let's deploy the Streamlit app on Railway, a modern app hosting platform. If you don't already have an account, sign up using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the Fireworks AI one-click starter template (or click the button below) to deploy it instantly on Railway.

Review the settings and click Deploy; the deployment will kick off immediately. Once the deployment completes, the Streamlit app will be available at a default xxx.up.railway.app domain - launch this URL to access the web interface. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.