LangChain Decoded: Part 3 - Prompts
An exploration of the LangChain framework and modules in multiple parts; this post covers Prompts.
In this multi-part series, I explore various LangChain modules and use cases, and document my journey via Python notebooks on GitHub. The previous post covered LangChain Embeddings; this post explores Prompts. Feel free to follow along and fork the repository, or use individual notebooks on Google Colab. Shoutout to the official LangChain documentation though - much of the code is borrowed or influenced by it, and I'm thankful for the clarity it offers.
Over the course of this series, I'll dive into the following topics:
- Models
- Embeddings
- Prompts (this post)
- Indexes
- Memory
- Chains
- Agents
- Callbacks
Getting Started
LangChain is available on PyPi, so it can be easily installed with pip. By default, the dependencies (e.g. model providers, data stores) are not installed, and should be installed separately based on your specific needs. LangChain also offers an implementation in JavaScript, but we'll only use the Python libraries here.
LangChain supports several model providers, but this tutorial will only focus on OpenAI (unless explicitly stated otherwise). Set the OpenAI API key via the OPENAI_API_KEY environment variable, or directly inside the notebook (or your Python code); if you don't have the key, you can get it here. Obviously, the first option is preferred in general, but especially in production - do not commit your API key accidentally to GitHub!
Follow along in your own Jupyter Python notebook, or click the link below to open the notebook directly in Google Colab.

# Install the LangChain package
!pip install langchain
# Install the OpenAI package
!pip install openai
# Configure the API key
import os
openai_api_key = os.environ.get('OPENAI_API_KEY', 'sk-XXX')LangChain: Prompts
Large language models (LLMs) require a lot of time, data, money, and compute resources for training and optimization. Re-training the entire model is often not a practical endeavour for the model consumers; instead, fine-tuning the model on a specialized dataset, or eliciting specific responses based on additional context provided in the request (aka prompt), are the currently preferred ways for dealing with this problem. Unless you have unique, sensitive or private data to fine-tune the model with, prompt design/tuning is often sufficient for most use cases. In this post, we'll explore the LangChain Prompts module, the capabilities it offers, and some of the nuances of prompt engineering.
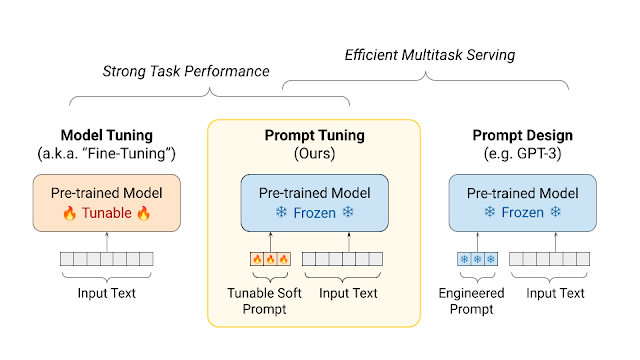
Good prompts are specific, descriptive, offer context and helpful information, cite examples, and provide guidance about the desired output/format/style etc. Prompt templates are a reproducible way to generate, share and reuse prompts. Prompt engineering, an emerging but possibly transient field associated with the development and fine-tuning of prompts, requires a combination of deep human expertise, machine learning techniques, trial-and-error, and of course patience!

A well constructed prompt template generally has the following sections:
- Instructions - system instructions that define the model response/behavior
- Context - helpful information passed via the prompt, sometimes with examples
- User input - the actual user input or question
- Output indicator - marks the beginning of the model response
Before we get discuss templates, let's explore a couple of basic prompt examples. In the first one, we ask the model about a recent event or occurrence.
# Ask the LLM about a recent event/occurence
from langchain.llms.openai import OpenAI
llm = OpenAI(model_name='text-davinci-003', openai_api_key=openai_api_key)
print(llm("What is LangChain useful for?"))
*** Response ***
LangChain is a blockchain-based platform that is useful for streamlining the process of finding and connecting with language tutors and learners worldwide.This is clearly not the result we expected! At the time of writing, OpenAI LLMs were trained on a corpus of data relevant up to September 2021, and hence the models are unable to answer anything that happened subsequently without additional context. This is the crux of prompt engineering versus fine-tuning - with sufficient context, the models are able to work around their knowledge limitations.
# Ask the same question again, but with relevant context
prompt = """You are a helpful assistant, who can explain concepts in an easy-to-understand manner. Answer the following question succintly.
Context: There are six main areas that LangChain is designed to help with. These are, in increasing order of complexity:
LLMs and Prompts: This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.
Chains: Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
Data Augmented Generation: Data Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answering over specific data sources.
Agents: Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.
Memory: Memory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
Evaluation: Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
Question: What is LangChain useful for?
Answer: """
print(llm(prompt))
*** Response ***
LangChain is useful for managing prompts, optimizing prompt performance, creating end-to-end chains, generating data-augmented content, creating agents, persisting state with memory, and evaluating generative models.In reality, prompt attributes and data will unlikely be hardcoded; LangChain recognizes this and provides the PromptTemplate class to construct the prompt based on pre-defined attributes as well as user input. Let's take a different example to illustrate this feature. Here the question is not embedded in the prompt template and is instead passed at runtime.
# Use a template to structure the prompt
from langchain import PromptTemplate
template = """You are a helpful assistant, who is good at general knowledge trivia. Answer the following question succintly.
Question: {question}
Answer:"""
prompt = PromptTemplate(template=template, input_variables=['question'])
question = "Who won the first football World Cup?"
print(llm(question))
*** Response ***
Uruguay won the first FIFA World Cup in 1930.By default, PromptTemplate treats the provided template as a Python f-string using the f-string templating format. You can change this to jinja2 by using the template_format argument; just ensure jinja2 is installed first. You can also customize the default prompt template to accommodate more attributes - see this example on customizing templates.
Prompts and prompt templates can also be used in complex workflows with other LangChain modules using chains. I'll dive deeper in the upcoming post on Chains but, for now, here's a simple example of how prompts can be run via a chain.
# Use a chain to execute the prompt
from langchain.chains import LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm)
print(llm_chain.run(question))
*** Response ***
Uruguay.You can save the prompt template to a JSON or YAML file in your filesystem for easy sharing and reuse. You can also load prompt templates from the LangChainHub using the lc://prompts/conversation/myprompt.json argument.
# Save prompt template to JSON file
prompt.save("myprompt.json")
# Load prompt template from JSON file
from langchain.prompts import load_prompt
saved_prompt = load_prompt("myprompt.json")
assert prompt == saved_prompt
print(llm(question))To help the model generate better responses, you can "train" it via few shot examples in the prompt itself. While this could, in theory, be done within the prompt text itself, LangChain offers the FewShotPromptTemplate class to do this in a more structured fashion.
# Guide the model using few shot examples in the prompt
from langchain import PromptTemplate, FewShotPromptTemplate
examples = [
{ "question": "How can we extend our lifespan?",
"answer": "Just freeze yourself and wait for technology to catch up."},
{ "question": "Does red wine help you live longer?",
"answer": "I don't know about that, but it does make the time pass more quickly."},
{ "question": "How can we slow down the aging process?",
"answer": "Simple, just stop having birthdays."}
]
template = """
Question: {question}
Answer: {answer}
"""
prompt = PromptTemplate(input_variables=["question", "answer"], template=template)
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=prompt,
prefix="Respond with a funny and witty remark.",
suffix="Question: {question}\nAnswer:",
input_variables=["question"],
example_separator=""
)
print(few_shot_prompt.format(question="How can I eat healthy?"))
print(llm(few_shot_prompt.format(question="How can I eat healthy?")))
*** Response ***
Respond with a funny and witty remark.
Question: How can we extend our lifespan?
Answer: Just freeze yourself and wait for technology to catch up.
Question: Does red wine help you live longer?
Answer: I don't know about that, but it does make the time pass more quickly.
Question: How can we slow down the aging process?
Answer: Simple, just stop having birthdays.
Question: How can I eat healthy?
Answer: Eat food from the ground and don't eat anything that can outrun you.If you have a large number of examples, you can use the ExampleSelector class to select and pass a subset of the examples to the model. You can also use the LengthBasedExampleSelector to filter examples based on the input length - this is useful when you are dealing with a limited context window. See this example for guidance on example selectors, including creating custom ones for your use case.
In contrast to LLMs, chat models (e.g. gpt-3.5-turbo) take messages as input. LangChain provides several classes to work with chat-based prompts. I covered one example in Part 1 - Models of this series; I'll extend that and offer a variation using prompt templates here.
# Use prompt templates with chat models
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
chat = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)
system_message="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(system_message)
human_message="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_message)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
messages = chat_prompt.format_prompt(input_language="English", output_language="Spanish", text="I'm hungry, give me food.").to_messages()
chat(messages)
*** Response ***
AIMessage(content='Estoy hambriento, dame comida.', additional_kwargs={})Sometimes, you may want the response to be in a more structured format rather than text - LangChain offers output parsers to help with this. Broadly speaking, you must define the desired output data structure, and then create a parser to populate the data structure based on specific instructions in the prompt template. I won't cover parsers here as the LangChain documentation is quite helpful.
The next post in this series covers LangChain Indexes - do follow along if you liked this post. Finally, check out this handy compendium of all LangChain posts.