Chat with PDF using LlamaIndex and LlamaParse
A step-by-step guide on chatting with a PDF document using LlamaIndex, LlamaParse and OpenAI.
Large language models (LLMs) offer an easy-to-use, natural language interface between you and your data. But, while they are trained on huge volumes of data, they don't really know much about your "private" data. Consequently, they cannot offer contextual responses by default. There are various solutions to tackle this problem, the most popular one being Retrieval Augmented Generation (or RAG, for short), which combines context from your data sources with LLMs at inference time to give you a more relevant response. This is where LlamaIndex comes in.
What is LlamaIndex?
LlamaIndex is an open-source project that provides a simple interface between LLMs and external data sources like APIs, PDFs, SQL etc. It provides indices over structured and unstructured data, helping to abstract away the differences across data sources. When working with LLM applications, LlamaIndex helps to ingest, parse, index, and process your data in conjunction with context added from external data sources as necessary.
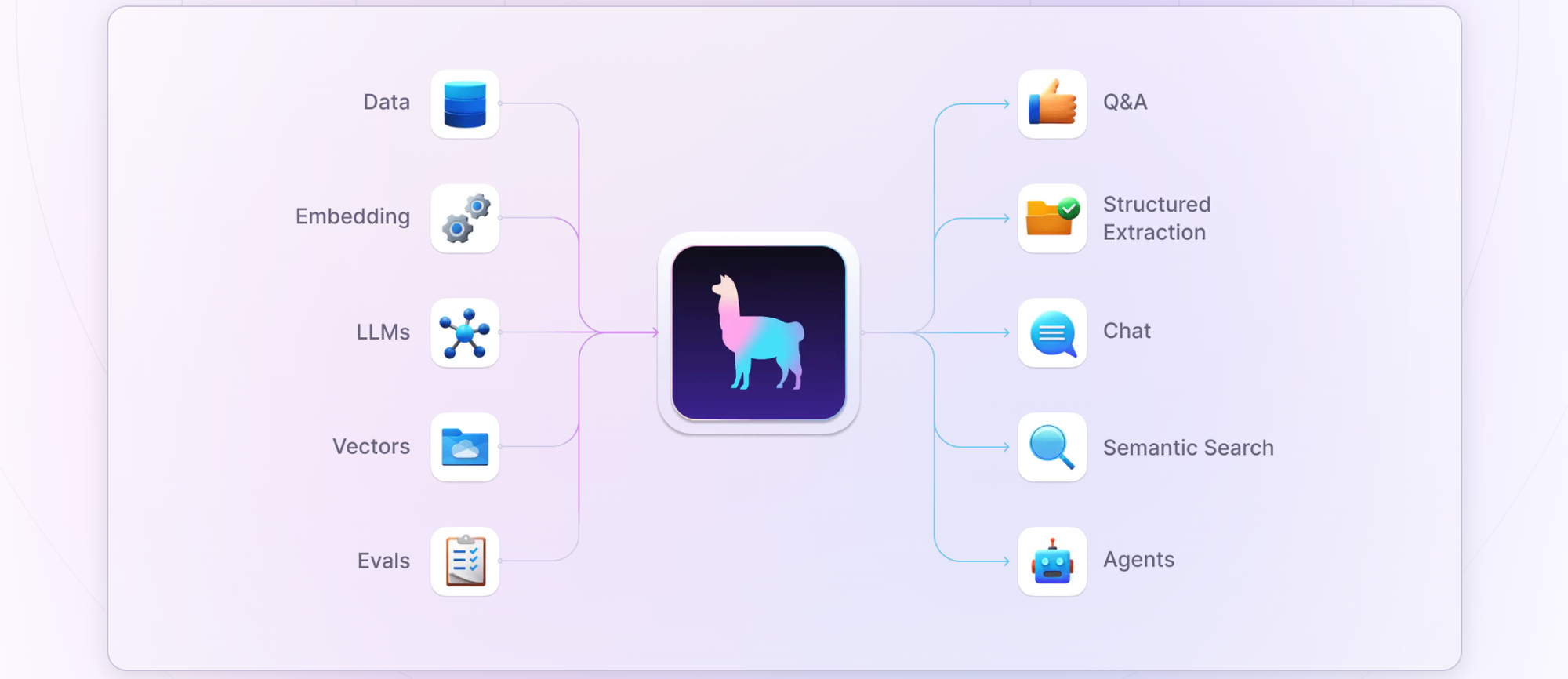
LlamaIndex offers tools to significantly enhance the capabilities of LLMs:
- Data connectors to ingest data from various sources in different formats
- Data indexes to structure data in vector representations for LLMs to consume
- Query engines as interfaces for question-answering on your data
- Chat engines as interfaces for conversational interactions with data
- Agents as complex, multi-step workers, with functions and API integrations
- Observability/Evaluation capabilities to continuously monitor your app
What is LlamaParse?
LlamaCloud is a fully managed service for data parsing, ingestion, indexing, and retrieval, allowing you to launch production-ready LLM applications quickly. LlamaParse, on the other hand, is a fully managed document parsing solution, available both as part of LlamaCloud, as well as a standalone solution. For this walkthrough, sign up with LlamaCloud and create an API key. The free account is more than sufficient to play with the parsing capabilities.
Use Streamlit and LlamaParse to Chat with PDF
To chat with a PDF document, we'll use LlamaParse to parse contents, LlamaIndex to create a vector index representation, and OpenAI to store/retrieve the vector embeddings. The OpenAI integration is transparent to the user - you just need to provide an OpenAI API key, which will be used by LlamaIndex automatically in the background. We'll wrap the whole interaction in a Streamlit web application for ease of development and deployment. Here's my streamlit_app.py file describing the entire flow; you can find the complete source code on GitHub.
import os, tempfile, streamlit as st
from llama_index.core import VectorStoreIndex
from llama_parse import LlamaParse
# Streamlit app config
st.subheader("Ask Llama")
with st.sidebar:
openai_api_key = st.text_input("OpenAI API key", type="password")
llama_cloud_api_key = st.text_input("LlamaCloud API key", type="password")
source_doc = st.file_uploader("Source document", type="pdf")
col1, col2 = st.columns([4,1])
query = col1.text_input("Query", label_visibility="collapsed")
# Session state initialization for documents and retrievers
if "loaded_doc" not in st.session_state or "query_engine" not in st.session_state:
st.session_state.loaded_doc = None
st.session_state.query_engine = None
submit = col2.button("Submit")
# If the "Submit" button is clicked
if submit:
if not openai_api_key.strip() or not llama_cloud_api_key.strip() or not query.strip():
st.error("Please provide the missing fields.")
elif not source_doc:
st.error("Please upload the source document.")
else:
with st.spinner("Please wait..."):
# Set API key environment variables
os.environ["OPENAI_API_KEY"] = openai_api_key
os.environ["LLAMA_CLOUD_API_KEY"] = llama_cloud_api_key
# Check if document has already been uploaded
if st.session_state.loaded_doc != source_doc:
try:
# Initialize parser with markdown output (alternative: text)
parser = LlamaParse(language="en", result_type="markdown")
# Save uploaded file temporarily to disk, parse uploaded file, delete temp file
with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp_file:
tmp_file.write(source_doc.read())
documents = parser.load_data(tmp_file.name)
os.remove(tmp_file.name)
# Create a vector store index for uploaded file
index = VectorStoreIndex.from_documents(documents)
st.session_state.query_engine = index.as_query_engine()
# Store the uploaded file in session state to prevent reloading
st.session_state.loaded_doc = source_doc
except Exception as e:
st.error(f"An error occurred: {e}")
try:
response = st.session_state.query_engine.query(query)
st.success(response)
except Exception as e:
st.error(f"An error occurred: {e}")Deploy the Streamlit App on Railway
Let's deploy the Streamlit app on Railway, a modern app hosting platform. If you don't already have an account, sign up using GitHub, and click Authorize Railway App when redirected. Review and agree to Railway's Terms of Service and Fair Use Policy if prompted. Launch the Llama-Index one-click starter template (or click the button below) to deploy it instantly on Railway.

Review the settings and click Deploy; the deployment will kick off immediately. This template deploys multiple apps - you can see the details in the template.
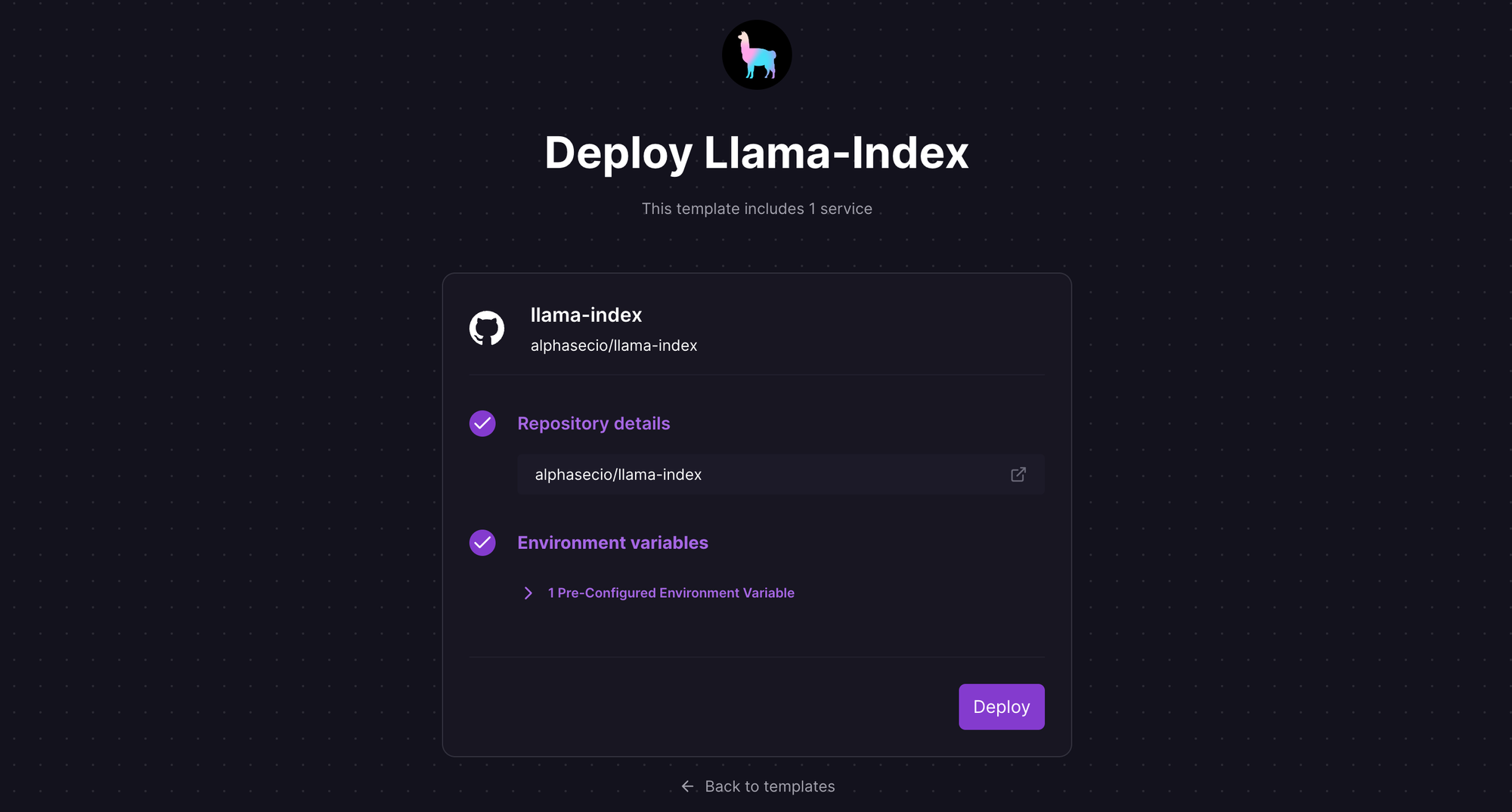
Once the deployment completes, the Streamlit apps will be available at default xxx.up.railway.app domains - launch the respective URLs to access the web interfaces. If you are interested in setting up a custom domain, I covered it at length in a previous post - see the final section here.
When the Streamlit app is ready, provide the OpenAI and LlamaCloud API keys, upload the source document, and ask away! In the example below, I uploaded Alphabet's latest quarterly earnings report, and asked for specific information from the filing.
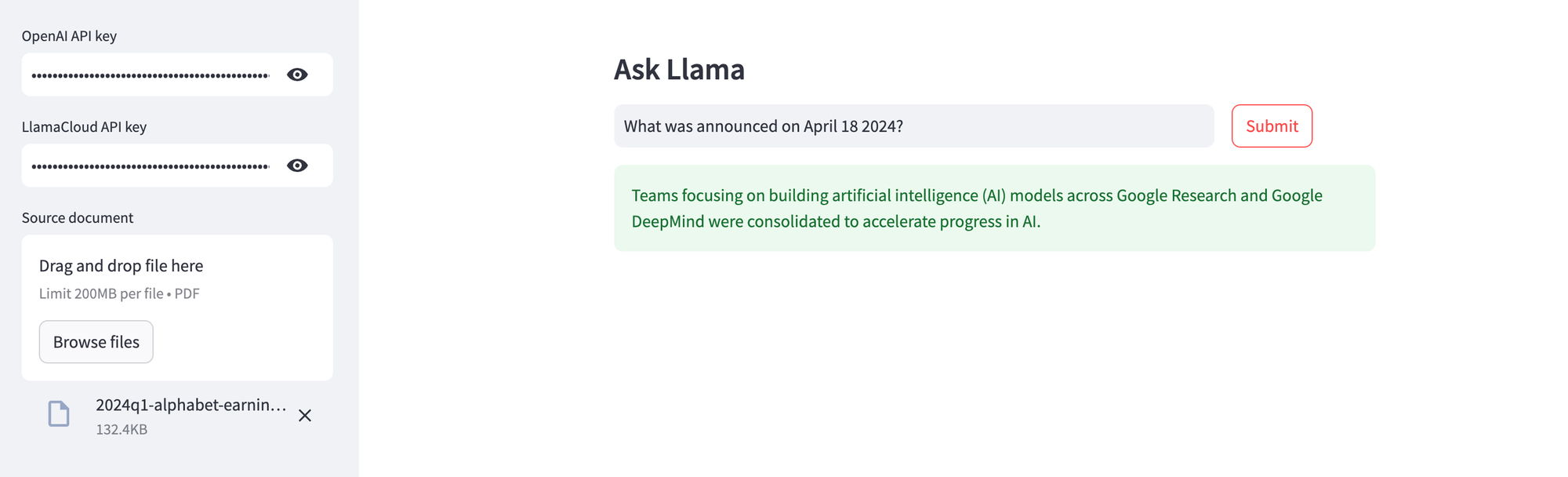
As you can see from the source document (snippet) below, the information retrieved is indeed accurate. Upload different PDF documents, and enjoy your very own "Chat with PDF" capability!
