Supercharge Web Scraping and Extraction with Firecrawl
A brief on Firecrawl, an open source tool for web scraping and data extraction.
Website crawling and content scraping technologies have been around for a while, with solutions like BeautifulSoup, Playwright, Scrapy, or Selenium among developer favourites. But, as web technologies themselves have gotten more expressive, dynamic and complex over the years, websites have become harder to scrape efficiently, and without toil. With the advent of large language models (LLMs), various startups and projects are now looking to redefine web scraping using LLM advancements in content understanding. Once such project is Firecrawl, which I'll explore today.
What is Firecrawl?
Firecrawl, by Mendable AI, is an open source service that turns websites into well-formatted markdown or structured data in just a few lines of code. You can scrape a web page or crawl an entire website, and even extract structured data with a single API. Traditional web scrapers can be finicky with certain websites, especially those with dynamic content rendered with Javascript, or with anti-bot measures in place, and can struggle with mapping extracted content to the desired schema.

Firecrawl's intelligent scraping and extraction abilities can deal with proxies, anti-bot mechanisms, dynamic content, and output parsing better than other scrapers. Firecrawl employs a variety of techniques to minimise bandwidth usage and avoid triggering anti-scraping measures. Granted, some of these capabilities are available in the hosted version, not the open-source version, but Firecrawl offers a decent free tier (500 credits, with each credit good for scraping or crawling a web page) to allow you to experiment with your use cases. Of course, Firecrawl does respect the rules set in a websites robots.txt file to balance the privacy needs of users. Before we move on to the next section, create an account with Firecrawl, and get your API key. If you prefer to self-host instead, read this guide.
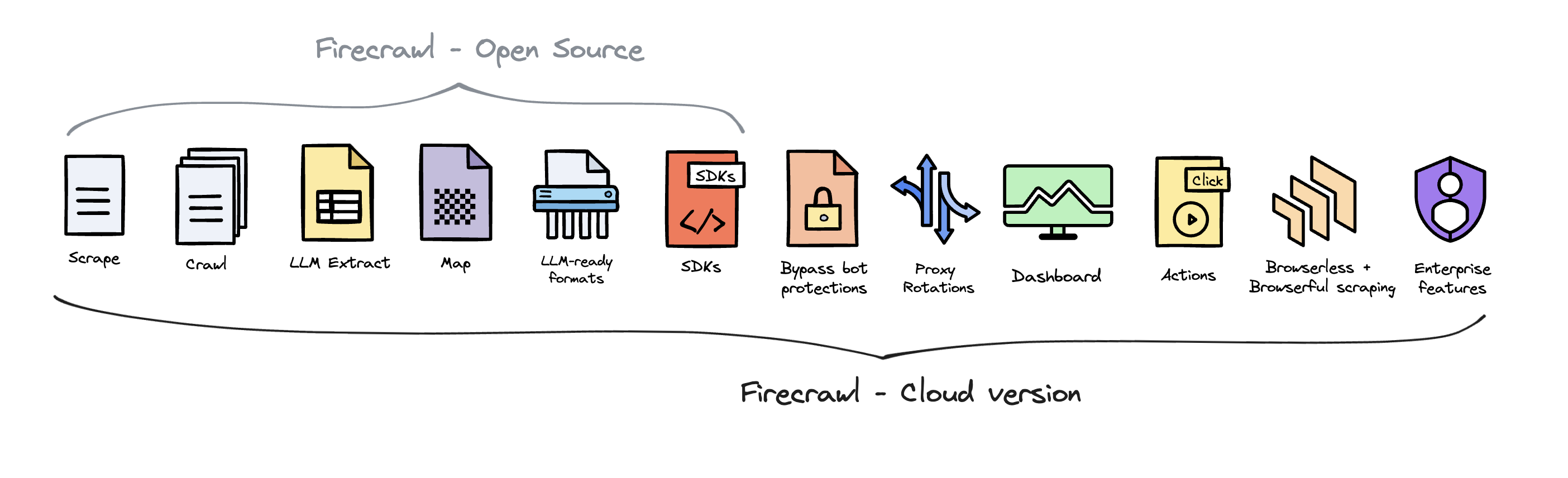
Scraping Web Pages with Firecrawl
Firecrawl can easily convert web pages into markdown text using the /scrape endpoint with just a few lines of code; here's sample Python code. You can specify the output format as Markdown, HTML, raw HTML, screenshot, links or as an extract. Refer to the API reference for more details about the parameters.
# pip install firecrawl
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Scrape a website:
scrape_result = app.scrape_url('firecrawl.dev', params={'formats': ['markdown', 'html']})
print(scrape_result)To explore Firecrawl's scraping capabilities, I created a simple cron job that periodically retrieves matching emails from a mailbox, extracts the URLs from the email body, scrapes and summarises the content of each URL, and resends the email with the URLs and their summaries.
The /scrape (with extract) endpoint allows you to extract structured data from scraped pages. You can also extract without a schema by just passing a prompt to the endpoint and letting the LLM infer the data structure. Before you scrape an endpoint, you can perform various actions - this is useful for dealing with dynamic content, page navigation, or accessing content that requires user interaction. Firecrawl just announced agentic capabilities, as well as change tracking for the scrape endpoint, making it immensely more useful.

Crawling Websites with Firecrawl
Instead of scraping a single (or more) web page, Firecrawl can also recursively search through an URL's subdomains using the /crawl endpoint. If a sitemap is found, Firecrawl will follow it, else it will recursively uncover all subpages, and gather content from each page as it is visited. If you wish, you can include a webhook parameter that sends a POST request to your URL when crawled. Firecrawl also supports change tracking with the crawl endpoint now. Here's sample Python code from their website.
# pip install firecrawl
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Crawl a website:
crawl_result = app.crawl_url(
'docs.firecrawl.dev', {
'exclude_paths': ['blog/.+'],
'limit': 5,
}
)
print(crawl_result)Extracting Structured Data with Firecrawl
While the /scrape endpoint supports structured data extraction, Firecrawl also provides a dedicated /extract endpoint (in Beta) with additional capabilities. The endpoint accepts both a well-defined schema, or an LLM prompt, to infer the data to be extracted. The enableWebSearch = true parameter allows Firecrawl to follow links outside the specified domain to enrich the results.
# pip install firecrawl-py
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Define schema to extract contents into
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
extract_result = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
print(extract_result)