Llama Firewall: Comprehensive Guardrails for LLM Applications
A brief on Llama Firewall from Meta, a comprehensive system of guardrails for securing LLM applications and agents.
Once confined to conversational chatbots (and chat with PDF use cases), large language models (LLMs) have rapidly evolved into complex, autonomous agents. These agents are now being entrusted with high-value tasks like editing production code, orchestrating payment workflows, analysing critical security incidents, and making decisions based on potentially untrusted inputs. While this increased autonomy greatly expands the universe of addressable use cases, it also gives rise to a new class of security risks that traditional cybersecurity tools are ill-equipped to handle. Prompt injection, insecure code generation, and agent misalignment are just a few examples of the emerging, sophisticated threats. This fundamental change necessitates a more system-level defence versus merely looking at this as an input/output filtering problem.
What is Llama Firewall?
After a flurry of Llama model releases and content safety tools like Llama Guard and Prompt Guard, Meta recently announced the Llama Firewall project - an open-source, system-level, security-focused guardrail framework. It is designed as a modular and adaptive "final" layer of defence against the unique security risks posed by LLM-powered applications and agents. Drawing parallels to established open-source tools like Snort or Zeek in traditional cybersecurity, Meta positions Llama Firewall as a real-time security control for layered defence.
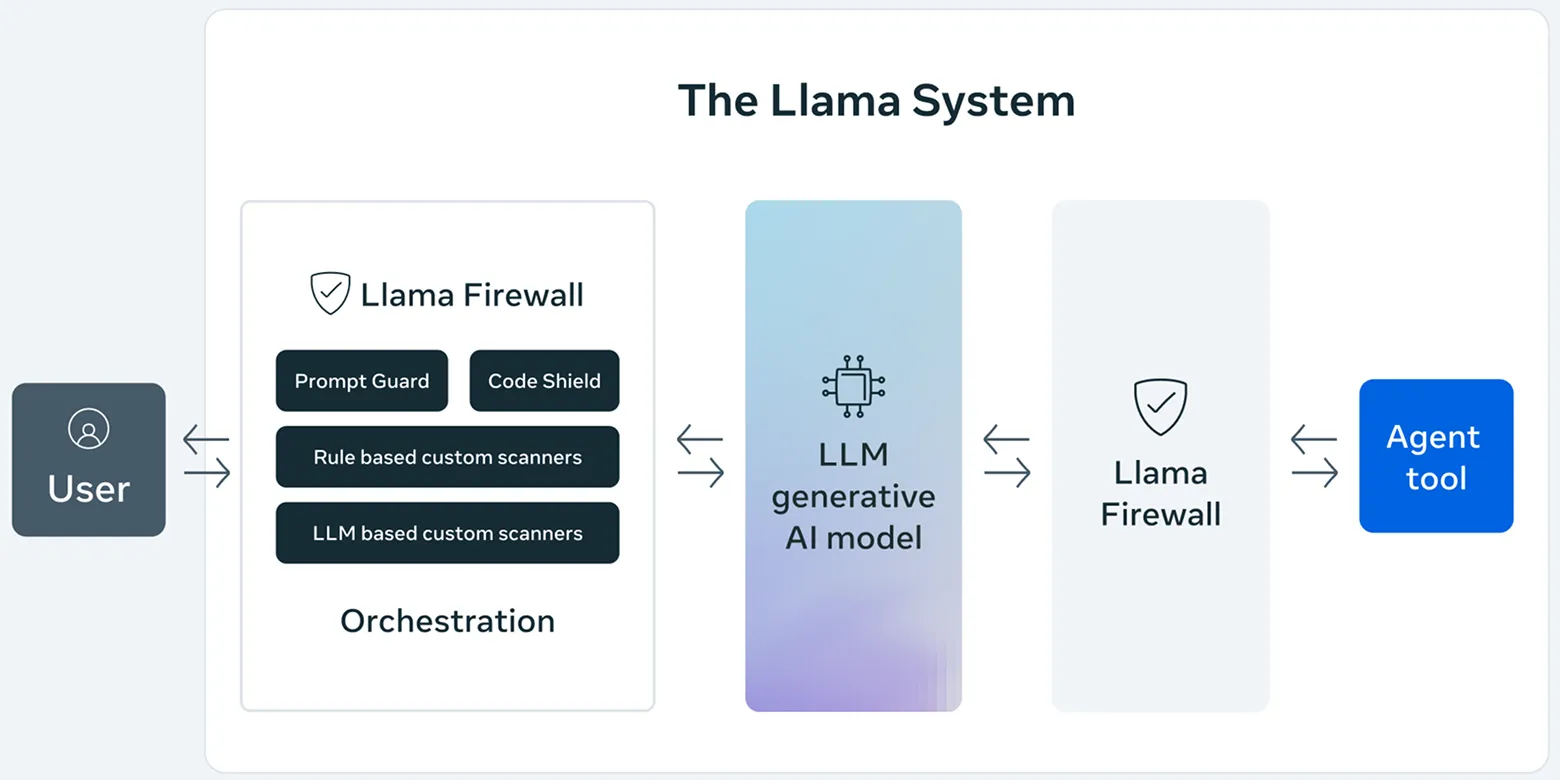
Llama Firewall integrates three specialised guardrails - PromptGuard, CodeShield and Agent Alignment Checks - to tackle the prompt injection, insecure code generation, and agent misalignment risks respectively.
- PromptGuard: As covered here, this is a powerful classifier model for protecting LLM application inputs, as well as untrusted data source inputs, from malicious prompts and jailbreaks.
- CodeShield: This is a fast and extensible static analysis engine, aimed at preventing the generation of insecure or malicious code by coding agents. It supports syntax-aware pattern matching across eight programming languages.
- Agent Alignment Checks: This is an experimental, chain-of-thought auditor that inspects an agent's reasoning trace to assess whether its actions are semantically aligned with the user's objectives.
Overall, Llama Firewall's architectural philosophy revolves around a unified policy engine that allows developers to define custom security policies and remediation strategies, making it both powerful and extensible at the same time. While this is an initial release, Meta seems committed to the long-term success of this project, with numerous capabilities like support for multimodal agents, reduced latency, expanded threat coverage, and robust benchmarking methods on the way.