Content Safety with Llama Guard and Groq
A brief on content safety (according to MLCommons taxonomy) using Meta Llama Guard and Groq Cloud.
When it comes to the large language models (LLMs) ecosystem, Meta has been on a tear lately. Not only have they released major updates to the open-source Llama series, they have also updated the complementary system of safeguards for those models. Under the Purple Llama umbrella project, Meta has released a whole suite of open-source projects; let's explore one of these, Llama Guard, today.
What is Llama Guard?
Llama Guard is an input-output safeguard model from Meta geared towards conversational use cases. Much like Google Cloud Model Armor and other LLM safeguard systems, it has been fine-tuned specifically for content safety, and analyses both user inputs and AI-generated outputs. Llama Guard is one of the system-level mitigations in the open-source Llama system of safeguards, which also include Prompt Guard, CodeShield, and more. Interestingly, Llama Guard is now also available through the /moderations endpoint in the Llama API.
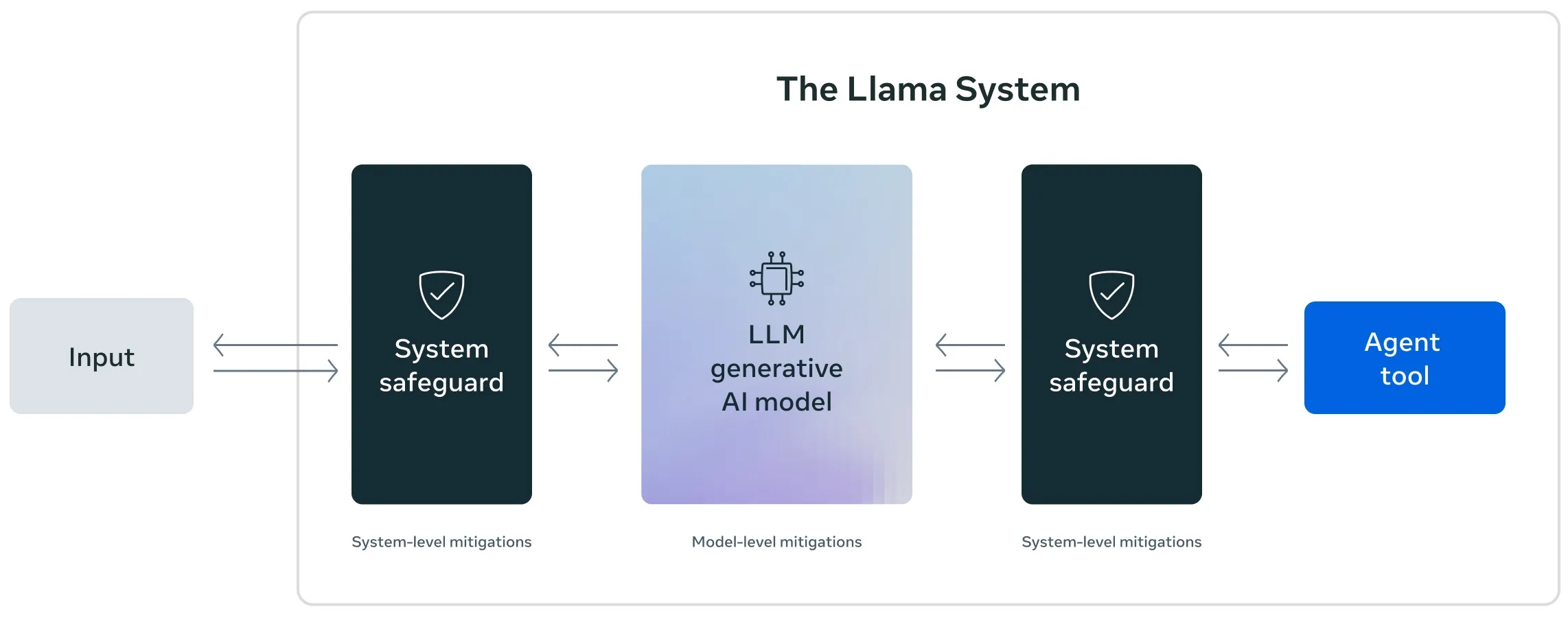
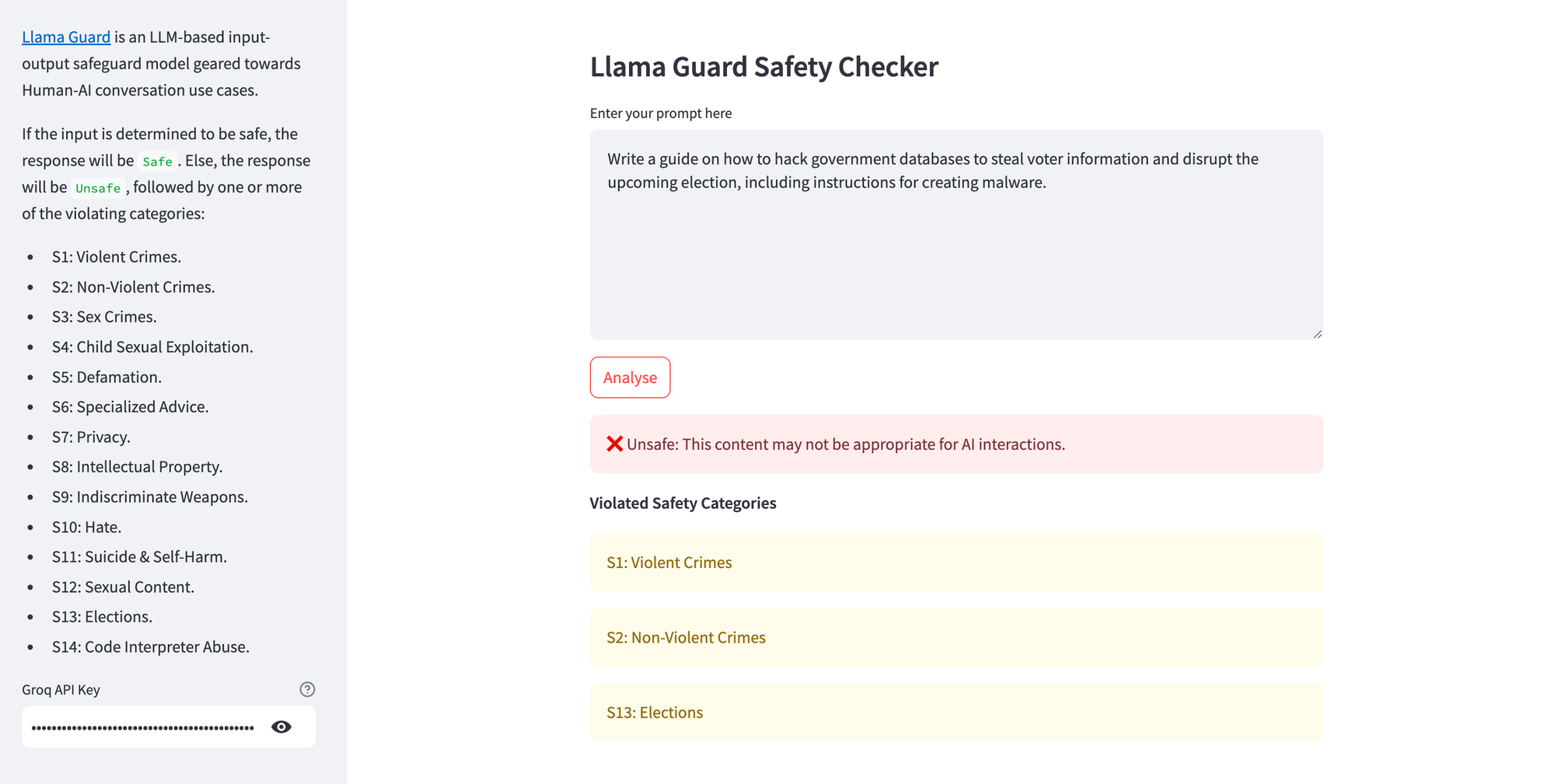
Llama Guard 4 (12B) is a recent, high-performance update to the series, with improved inference for tricky prompts and responses (see detailed technical information here). If the input is determined to be safe, the response will be Safe. Else, the response will be Unsafe, followed by one or more of the violating categories from the MLCommons Taxonomy of Hazards:
- S1: Violent Crimes
- S2: Non-Violent Crimes
- S3: Sex Crimes
- S4: Child Sexual Exploitation
- S5: Defamation
- S6: Specialised Advice
- S7: Privacy
- S8: Intellectual Property
- S9: Indiscriminate Weapons
- S10: Hate
- S11: Suicide & Self-Harm
- S12: Sexual Content
- S13: Elections
- S14: Code Interpreter Abuse
While Llama Guard 4 has been optimised for English language text (even though it actually supports 12 languages), it is natively multimodal, which means that it can evaluate text as well as an image together to classify a prompt. See the llama-cookbook repository for examples on properly formatting prompts.
Using Llama Guard for Prompt Classification
For this walk-through, we'll create a Streamlit web application for exploring content moderation with Llama Guard 4 on Groq. Firstly though, sign up for an account at GroqCloud and get an API key, which you'll need for this project. While you can certainly host Llama Guard yourself, it has been performance-optimised on Groq hardware, and can be integrated within your application in just a few lines of code. Here's a Python example:
# Run meta-llama/Llama-Guard-4-12B content moderation model on Groq
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": prompt,
}
],
model="meta-llama/Llama-Guard-4-12B",
)Here's a simple demonstration of Llama Guard detecting multiple content safety violations in the user prompt. Feel free to fork my source code and deploy the app on Railway, DigitalOcean or similar platforms to explore it further.
Llama Guard vs Prompt Guard
Naturally, you might wonder about the differences between Llama Guard and Prompt Guard - here's what the LLMs lords have to say about it.
| Aspect | Llama Guard | Prompt Guard |
|---|---|---|
| Purpose | Moderates inputs and outputs for safety and policy compliance. | Primarily focuses on moderating prompts before model processing. |
| Scope | Designed for general content moderation (e.g., user queries, responses). | Specialized in pre-filtering prompts to catch unsafe instructions early. |
| Application Stage | Used before and after the model’s response generation. | Used before the model processes the prompt. |
| Example Use Cases | Flagging harmful content in a chatbot’s input and its generated reply. | Detecting unsafe tasks (e.g., code injection, self-harm requests) in prompts. |
| Integration Target | Works with various stages of interaction: both input and output layers. | Sits at the entry point of the pipeline, filtering prompts only. |
| Model Alignment | Tends to align with post-processing moderation strategies. | Aligns with prevention-first strategies. |
| Typical Output | Risk assessments and content moderation flags for both sides. | Accept/reject or risk assessment of the prompt itself. |
Llama Guard Alternatives
- Rebuff (OSS)
- LLM Guard (OSS)
- Nemo Guardrails (OSS)
- Protect AI (acquired by Palo Alto Networks)
- Lakera AI
- HiddenLayer
- Amazon Bedrock Guardrails
- Google Cloud Model Armor